ポスト
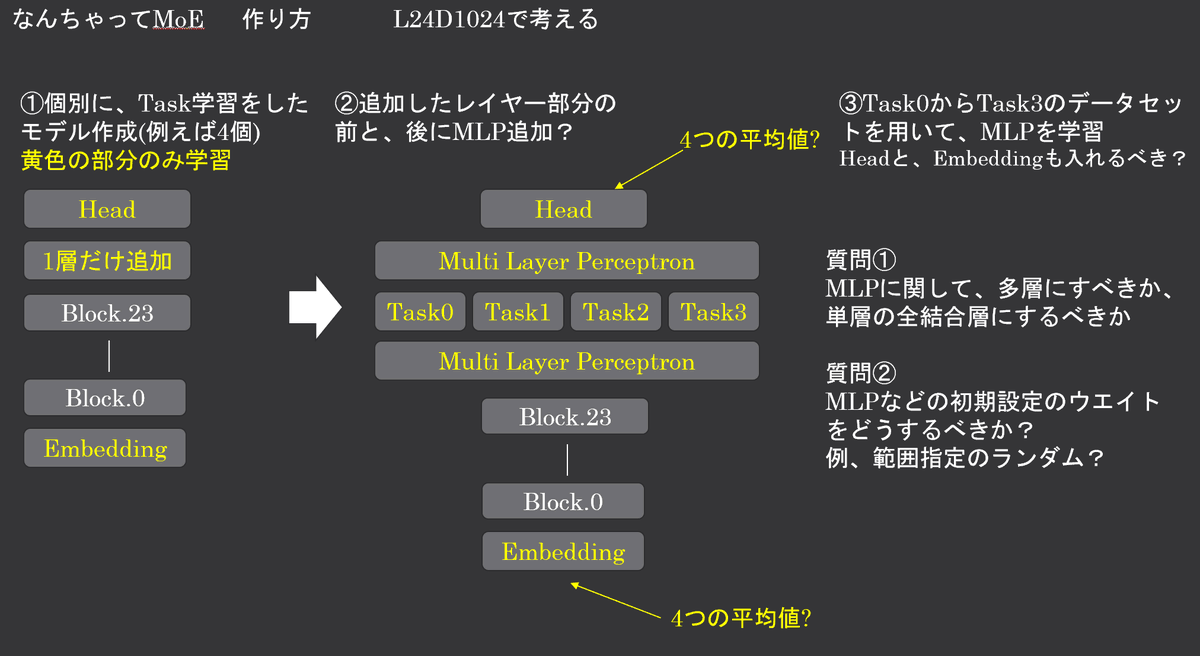
安直ですが、元モデルについて、各タスクiで層を積み増して 、元モデルのブロックは凍結して、task_i+emb_i+head_iのようにモデルを更新。MoEの初期値は emb_iとhead_iは平均化、task_iは 並列につなげて、全結合層は自作して、元のモデルに積む。最後に、目的とするタスクでファインチューニング pic.twitter.com/8eFRi6t5Uv
メニューを開くみんなのコメント
メニューを開く
ありがとうございます。すごく面白そうです 以下の画像のようなイメージでしょうか? RNNで、トークンごとに、参照レイヤーが変化すると思うので、非常に興味があります pic.twitter.com/GT9pBOGFSi
人気ポスト
EXOの本国ネキが1番怖かったってオンマが言ってた (これ単コンじゃなくてMMA)
これは偶然ホラーになってしまっているマックの壁紙
二人とも凄く美形で知名度もありお似合いなはずで、 オラッすげーだろ憧れろ!みたいな記事なのに、なんだか服装や写真がシュールで憧れられない。 皆ねずみ色の服に黒髪。 ドレスコード?? #広瀬すず #山崎賢人
残業してクッタクタで会社でた後、お手洗いの鏡にうつった自分の顔がすごく疲れてて、とりあえずリップだけでも塗り直すか…って塗り直したんだけど、塗った途端顔が明るくなってちょっと気分良く帰れた🥲 前にも投稿したマキアージュなんだけど本当お気に入り。絶対リピする!
親・弟・友達・担任・学年主任 「修 学 旅 行 で す よ ?」
ガチこれなんだけどどないしたら良いの
この子がいることを小学生が知らせてくれました。朝生きていてまだ生きてるんだと… 元気になったことをまた知らせに行こうと思います☺ もうすぐ1歳です👏👏👏
同世代の男性であれば何のパーツかすぐ分かるって本当ですか?
カレー4皿分の材料。 にんじん小4/3本。←まだ許せる。 玉ねぎ中1と3/8個。 8分の3だと?? これは難儀だね。 残りの8分の5個はどうすんの? 山本ゆりさん@syunkon0507にしばかれるぞ。
トレンド12:19更新
- 1
アニメ・ゲーム
学級閉鎖
- 学校閉鎖
- 臨時休校
- 学校休み
- 学マス
- 地獄絵図
- スマブラ
- 落ちたな
- 2
エンタメ
SUPER EIGHT
- アリーナツアー
- EIGHT
- 大倉忠義
- 発売決定
- スーパー
- 3
エンタメ
古畑任三郎
- 一挙放送
- 午後1時
- フェアな殺人者
- 30周年
- 4
ITビジネス
スマホ版
- 30日まで
- マインクラフト
- 15周年
- マイクラ
- 70%
- ログイン
- スマホ
- 5
エンタメ
黒人の侍
- アサシンクリード
- 6
ニュース
四条烏丸
- 下京区白楽天町
- 京都市下京区
- 白楽天町
- 京都市消防局
- 出動要請
- 爆発火災
- ヘリコプター
- 火災が発生
- 7
フリー入場
- クロスストア
- 入場制限
- FS
- 8
エンタメ
製作決定
- ケイン
- 9
ITビジネス
iPhoneのタッチ決済
- エアペイ
- Tap to Pay
- タッチ決済
- アップル
- 決済オタク
- Apple Pay
- デビットカード
- iPhone
- 10
スタンバイパス
- スニーク
- モバイルオーダー
- ファンタジースプリングス
- DPA
- 東京ディズニーシー
- ラプンツェル
- TDR



