- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く
学部1年生にGEO2R ncbi.nlm.nih.gov/geo/geo2r/ で発現差がある遺伝子をみつけろという課題をだしたんだけど滅茶苦茶な分割(例えばレプリケートを2分割)でも補正P値が0.05以下になる遺伝子は結構見つかってしまうので偽陽性避けるのは難しいんだなー、と改めて実感している。
メニューを開く

#統計 P値はパラメータの値の設定とデータの数値の相性の良さを表す指標の1つに過ぎません。 パラメータ (a, p) の値の設定とデータの数値の相性の良さは添付画像のようにプロットされることになります。 P値の本来の姿はこのように見て楽しめる複雑さになります。 x.com/genkuroki/stat… pic.x.com/uM7ysfN2jK
#統計 お勧めのGreenlandさんの講演スライドより P値を推定のための道具として扱わない誤りの繰り返しはやめるべき。 「差がない」という帰無仮説のnull P値単体を帰無仮説有意性検定(NHST)で使うだけなのは誤解の主な原因になっている。 biostatistics.ucdavis.edu/sites/g/files/… pic.x.com/ey1p8K9W3D x.com/genkuroki/stat…
メニューを開く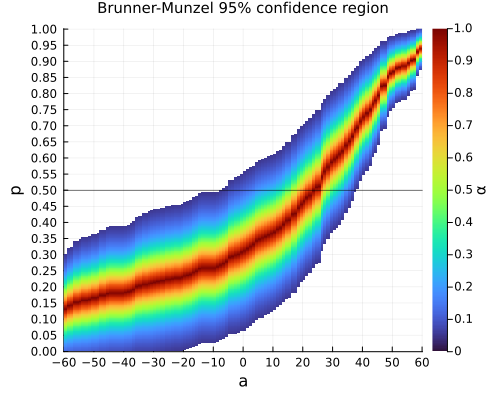
#統計 α=1.0の曲線(最も色が濃い茶色で表されている曲線)はaまたはpを固定したときに得られるpまたはaの点推定値を表しています。 もしくは、データの数値と相性がもっともよいaとpの組み合わせ全体を表している。 P値で色を付けています。 github.com/genkuroki/publ… pic.x.com/O2sxupjeb8
メニューを開く


#統計 95%信頼領域、99%信頼領域、P値関数のヒートマップを比較するために3枚まとめて投稿してみる。 個人的には、ナマのヒートマップ(3枚目)よりも、5%や1%の人為的な(科学的必然性皆無の)閾値設定の影響が見える1枚目と2枚目のグラフの方が3枚目よりも好みかも。 github.com/genkuroki/publ… pic.x.com/jg3WrKjYo4
メニューを開く
#統計 続き 添付画像は上の投稿のデータの数値の場合のp=1/2の場合(XとY+aが互角になる場合)に制限したハンデaに関するP値関数のグラフです。 今回はMann-WhitneyのU検定のP値関数も同時プロットしています。BM検定のP値関数よりも幅が狭くなっている。続く github.com/genkuroki/publ… pic.x.com/XP8tmMJsBQ
メニューを開く
#統計 BM検定に付随する(a,p)の信頼領域の例3/3 上では「互角」を仮定していたので、p=1/2と設定されていた。pの値も動かしたときのP値≥5%の領域に色を付けてプロットしたものが添付画像のグラフである。 これはBrunner-Munzel検定に付随する95%信頼領域の具体例。 github.com/genkuroki/publ… pic.x.com/rTeJRh9Swj
メニューを開く
"p値ベースの分析結果の1/3が偽陽性" みんなうっすらと知ってた x.com/shunk031/statu…
「p値って何かわかりますか??」からの「p値ベースの分析結果の1/3が偽陽性です」 インパクトすごいなこの論文 False Positives in A/B Tests | Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining dl.acm.org/doi/10.1145/36… #kdd24_reading pic.x.com/UTThvrM3fR
メニューを開く

「p値って何かわかりますか??」からの「p値ベースの分析結果の1/3が偽陽性です」 インパクトすごいなこの論文 False Positives in A/B Tests | Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining dl.acm.org/doi/10.1145/36… #kdd24_reading pic.x.com/UTThvrM3fR
メニューを開く
#統計 添付画像は、下川敏雄氏の講義スライドp.10 waidai-csc.jp/updata/2023/08… とほぼ同じ設定で、平均が等しい2つの正規分布について標準偏差の比s₂/s₁を変えながら、P値<5%となる確率を計算した結果です。 MW=Mann-WhitneyのU検定ではその確率が大きく上昇しています。続く github.com/genkuroki/publ… pic.x.com/lG4Lm2FSPV
メニューを開く
#統計 添付画像は、母集団分布1,2がそれぞれ平均が0で標準偏差が1,4の正規分布の場合の(不等母分散の場合の)、Student, Welchのt検定、Mann-WhitneyのU検定、Brunner-Munzel検定でのP値がα以下になる確率(αに近い方が良い)のグラフです。続く github.com/genkuroki/publ… pic.x.com/HWcMFlVQ8w
メニューを開く
>ベクトルの次元が高くなるにつれ、0に近い値ばかり出るようになって、1や-1に近い値が出にくくなる >「値1−α=1−P値」が大きければ大きいほど、「母相関係数(あるいはその絶対値)は大きかろう」といえることになるわけです。これを「直交非尤度」とでも呼びましょう。 天才かこいつ…
メニューを開く
#統計 doi.org/10.3758/s13428… 翻訳引用【NHSTを使用しているすべての出版された心理学論文の半数に、検定統計量および自由度と一致しないp値が少なくとも1つ含まれていることがわかった。8つの論文のうち1つには、統計的結論に影響を与えた可能性のある著しく矛盾したp値が含まれていました。】
メニューを開く

某社MRが「有意差があります!!」と持ってくるゾコーバのRCT。 軽症COVID19に対するゾコーバ (ensitrelvir) はプラセボと比較し主要5症状の消失が1日早い (p=0.4)とのこと。 効果はわずかであり、さらにサンプルサイズ各群230例でサンプル数各群340例とp値警察に処されそうなαエラーである。 さて.. pic.x.com/JCrY1xRQw8
メニューを開く
#統計 ①有意水準を例えば5%に設定して「P値<5%」かどうかのみを報告すると、多くの場合に科学的に無意味な有意水準の設定が必須になってしまうし、危険な二分法も強制されてしまう。 ②P値の具体的数値を「P値=2.5%」のように報告するなら、有意水準の設定は必須ではなくなる。 続く pic.x.com/PYkQcX8JrN x.com/genkuroki/stat…
#統計 バージョンアップ P値関数に至る道を具体例で説明 データの数値「n=20回中5回成功」が得られたときに、報告内容の制限を外して行くと、自然にP値関数の報告というアイデアに到達する。 添付画像はP値経路。続く github.com/genkuroki/publ… pic.x.com/WRCmS8KsxR x.com/genkuroki/stat…
メニューを開く
#統計 非ベイズとベイズの両方で相性の良さ(compatibility)という解釈を使うことについては、McElreathさんのStatistical RethinkingやGreenlandさん達の論文群を見てください。 ASA声明の原則1のP値の解釈にも"how incompatible" の形でcompatibleという言い方が登場しており、ある意味標準的。 x.com/genkuroki/stat…
#統計 通常の信頼区間だけではなく、ベイズ版の信用区間も compatibility interval と呼んで同じように解釈することの合理性については、McElreathさんのStatistical Rethinking 2nd ed. の3.2.2 (p.54)を参照。 Amrhein-Greenland (2022) journals.sagepub.com/doi/10.1177/02… も参照。 pic.x.com/7zQDanbe3O x.com/genkuroki/stat…
メニューを開く
#統計 解説 青線は「成功確率はpであるという検定仮説のP値」のグラフです。これをP値関数のグラフと呼びます。 大量の橙色の横線分達は高さαにプロットされた100(1-α)%信頼区間です。 #Julia言語 github.com/genkuroki/publ… pic.x.com/tAtLozF4fQ
メニューを開く

#統計 閾値をα=5%に固定したり(①❷)せずに済ますためには、P値を報告したり、すべての信頼水準の信頼区間全体を報告すればよい(②❸)。検定する仮説をp=0.5に制限せずに、すべての検定仮説p=aについて結果を報告すれば情報が大幅に増える(③)。P値関数!(③=❸) github.com/genkuroki/publ… pic.x.com/sxI5VJjfcO
メニューを開く
#統計 P値関数の概念に至るまで ①固定された有意水準α(例えばα=5%)で、帰無仮説θ=0が棄却されるか否かの2値的情報だけを報告。 ②帰無仮説θ=0のP値を報告。そのP値は帰無仮説θ=0が棄却される有意水準の下限なので、固定されていないすべての有意水準で棄却されるか否かを報告するのと同じ。 pic.x.com/oGEaTaWzbI
メニューを開く
DLBCL 一次治療→R-CHOP,Pola-R-CHP TLS(腫瘍崩壊症候群) 尿酸値、K、P値が基準値以上。 TLS予防薬 ・ラスブリガーゼ(入院での投与) ・フェブキソスタット(効果発現までに1~2日。予防的投与が必要)
メニューを開く
#統計 ASA声明が出たり、Greenlandさん達の活発な啓蒙活動にも関わらず、P値を「お墨付きを得るための道具」だと誤解している人達が多い。多くの教科書の説明は誤解の再拡散そのもの。 P値はデータの数値とモデルの相性の良さ(compatibility)を表す指標の1つに過ぎません。P値は推定のための道具。 x.com/genkuroki/stat…
#統計 お勧めのGreenlandさんの講演スライドより P値を推定のための道具として扱わない誤りの繰り返しはやめるべき。 「差がない」という帰無仮説のnull P値単体を帰無仮説有意性検定(NHST)で使うだけなのは誤解の主な原因になっている。 biostatistics.ucdavis.edu/sites/g/files/… pic.x.com/ey1p8K9W3D x.com/genkuroki/stat…
メニューを開く
#統計 あと、事後分布のグラフとたった1つのP値の計算結果を比較して、「ベイズの方が便利」だと誤解してしまうのは、たった1つのP値ではなく無数のP値を扱うP値関数の概念を知らない無知なベイズ統計宣伝者達に騙されているからです。 しかもそういうベイズ統計宣伝者達は無知の自覚が全くない。 x.com/genkuroki/stat…
#統計 上段が事後分布のグラフで、下段が通常のP値のグラフです。 母比率に関するP値は仮説「母比率はpである」ごとに得られます。P値を1つだけだと思うのは酷い誤り。無数にあるのでグラフに描くと分かり易い。 github.com/genkuroki/publ… pic.x.com/FBYZRhRin0
メニューを開く
#統計 上段が事後分布のグラフで、下段が通常のP値のグラフです。 母比率に関するP値は仮説「母比率はpである」ごとに得られます。P値を1つだけだと思うのは酷い誤り。無数にあるのでグラフに描くと分かり易い。 github.com/genkuroki/publ… pic.x.com/FBYZRhRin0
メニューを開く


#統計 note.com/cograph_data/n… では添付画像①のように事後分布をプロットし(縦軸のスケールはおかしい)、添付画像②のように述べていますが、添付画像③の下段のようにP値関数をプロットすれば、P値はベイズと同じくらい便利だと分かります。 ソースコード github.com/genkuroki/publ… #Julia言語 pic.x.com/cOQ97bkId0
メニューを開く
#統計 現代的なP値の解釈(本質的にASA声明の原則1)は P値はデータの数値と特定のモデルとそのパラメータの値に関する仮説の相性の良さ(compatibility)を表す。 これと整合性がない事柄について触れる場合には「ASA声明に反する内容であること」をきちんと断っておかないとまずいです。 x.com/genkuroki/stat…
#統計 閾値のαを設けて、仮説θ=aの(両側)P値がα未満かどうかを見ることは、特定のモデルの下で、仮説θ=aはデータの数値と(閾値αで)相性が悪いとみなされるかどうかを見ていることになります。 相性の良し悪しについての二分法に過ぎないので、仮説自体は肯定も否定もされない。
メニューを開く



monakaさんのプロンプト、またまた使わせて頂きました♪✨ありがとうございます🙏 僕は今、にじジャーニーから3つのp値を付与されているんですが、1代目p値から3代目p値までを順番に生成して比べてみようと思います! 地味ぃ~にテイストが変化してます💦… pic.x.com/xA2TQeLld6 x.com/monaka_mama3/s…
ハロウィーンシールが出るプロンプトです 皆さんの--pでどんなのが出るか見せてもらえたら嬉しい a various sticker collection on white background with margins, halloween --p (2枚目--style raw入り) そしてこれ、シール用紙に印刷したら実用できるのです😊 #nijijourneyv6 pic.x.com/jOx3ixS7TH
メニューを開く
#統計 100(1-α)%信頼区間にp=aが含まれることと、検定仮説p=aのP値α以上であることは同値なので、添付画像の信頼区間__達__のグラフから、検定仮説p=0.5のP値が7%より大きく8%より小さいことが分かる。 0%信頼区間は0.3の1点であり、これは母比率の点推定値である。 github.com/genkuroki/publ… pic.x.com/YaxOZEvAgz
メニューを開く
#統計 もしかしたらP値関数よりも信頼区間の方が分かりやすく感じる人もいるかもしれないと思って、信頼水準0%, 1%, …, 99%, 99.9% の101本の信頼区間を同時プロットしてみた。(0%信頼区間は点推定値に一致。0%とα=1.00が対応している。) ↓ x.com/genkuroki/stat…
#統計 以下のリンク先の疑問への解答は、P値の概念を使わずに、信頼水準1-αの信頼区間を高さαに線分としてプロットするだけでも得られます。 添付画像はデータ「20人中6人」から得られる母比率の信頼区間たちのグラフです。αは0.001, 0.01, 0.02, …, 1.00を動かした。続く github.com/genkuroki/publ… pic.x.com/zyrS553HLz x.com/georgebest1969…
メニューを開く
返信先:@stepn7danku1710他1人ラック靴を目指すのであれば、ステージ3は目指した方が良いですね、私はとてもステージ3の350値まで届かない為、ステージ2の250とp値のハイブリッドにしましたが、ステージ3だと赤石の上限値が違います。他のポストでも話してますが1walk切ると普通に歩いた方が稼げます🫡
メニューを開く
#統計 P値や信頼区間やP値の概念を十分に理解できなくなる主な原因の1つは、信頼区間として95%信頼区間しか考えなかったり、P値としてゼロ仮説θ=0のP値しか考えなかったりするからです。 すべての信頼水準の信頼区間達を同時に考えたり、すべての検定仮説θ=aのP値達を同時に考えれば理解が進みます。 pic.x.com/4FnhptsiMU x.com/genkuroki/stat…
#統計 「効果はない」型の帰無仮説のP値をnull P値と呼ぶ。 結果の要約をnull P値の数値に限定すると大量に情報を捨てていることになる。 信頼区間+点推定値に替えたり追加しても大量に情報を捨てていることになる。 数値aに関する「効果はaである」型の仮説達のP値全体まで情報を増やせる。 pic.x.com/XwNVUfiOjE x.com/genkuroki/stat…
メニューを開く
#統計 以下のリンク先の疑問への解答は、P値の概念を使わずに、信頼水準1-αの信頼区間を高さαに線分としてプロットするだけでも得られます。 添付画像はデータ「20人中6人」から得られる母比率の信頼区間たちのグラフです。αは0.001, 0.01, 0.02, …, 1.00を動かした。続く github.com/genkuroki/publ… pic.x.com/zyrS553HLz x.com/georgebest1969…
ベイズだと確率密度が出るので悩みはないのですが、普通の頻度論統計で95%CIであってもなんらかの分布(のようなもの?)があって、平均値のほうがより真の値に近くて、CIの端っこの方が真の値である可能性は下がる、、、ような気がするのですが、どうなのでしょう。
人気ポスト
川越まつり、りんご飴の件ですが 色んな方に見ていただきありがとうございます。 一緒に行った友だちのりんご飴も確認したところ、 そちらも同じようになっていました。 全体の写真を載せておきますので 明日、お祭りに行かれる方は このお店は十分にお気をつけください。
2024年11月1日より【フリーランス新法】が施行されます。 ワタシたちライバーにも影響はあり、簡単にいうと「イラストレーター様にイラスト制作作業をご依頼する際に条件をきっちり明示する必要がある」ということです。 詳しくはこちらを確認してくださいね! jftc.go.jp/freelancelaw_2…
記事につけられた小泉悠のコメント。お花畑と揶揄する向きもある反核運動のリアリズムについて。 朝日のサイトまで行かない人もいるので勝手ながら転載しておきます。 asahi.com/articles/ASSBD…
あ。
窓から見慣れない物が見える気がする 気のせいだよね?
明日、人と会えなくなるガーリックイン鶏皮揚げを冷やし忘れハイボールでキメるだけの動画
雪見だいふくにいちごミルク注ぐ ↓ 冷凍のいちごを散らす ↓ 神の食べ物が完成。
死んだはずの戦友が記憶喪失になり敵として再会…
五日ほど前に、エジプト・ギザの上空をパラグライダーで飛んでいた人が、ピラミッドの頂上にいる犬を発見。その際に撮影された動画。人のピラミッドへの登頂は禁止されているが、犬の登頂は想定外だったのでは。犬は後で無事に降りてきたことが確認されている。 via @ABC7
撮影しながら涙が出るなんて、もう2度とないと思う。紫金山・アトラス彗星、天の川、金星が作る宇宙のトライアングル。宇宙が見せてくれる奇跡だった。 #紫金山アトラス彗星 #Nikon



