- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く


#統計 ヒストグラムではなく累積分布関数をプロットした方が良い場合の典型例。 添付画像①は帰無仮説下での二項検定のP値の分布のヒストグラム。 ②は累積分布関数のグラフ。 ①ではP値の分布が一様分布で近似されていることは分からないが、②では一様分布の45度線で近似されていることがわかる。 pic.twitter.com/FZQnLCn3IO
メニューを開く
#統計 信頼区間はP値から、 (θの信頼水準1-αの信頼区間) = ((仮説θ=aのP値)≥αとなる数値aの範囲) で得られることが、信頼区間の理解では基本的。 そして点推定値は信頼水準0%の信頼区間。 Greenlandさん曰く、P値を推定の道具とみなさない誤りの繰り返しはもう止めろ。 x.com/genkuroki/stat…
#統計 超有名な疫学者&統計学者のSander Greenlandさんは【P値を推定のための道具として扱わないという重大な誤りを繰り返すことを止めろ】と言っています。 結構昔から「検定から推定へ」とよく言われていて私も正しいと思いますが、P値(関数)について理解すれば自動的にそうなります。 x.com/genkuroki/stat…
メニューを開く
#統計 それで正しいです。各数値aごとに、 P(a∈(θの信頼水準1-αの信頼区間)) = P((仮説θ=aのP値)≥α) なことから、これが 1-α で近似されること P((仮説θ=aのP値)<α) がαで近似されることは自明に同値になります。 信頼区間よりもP値の側でシミュレーションを実行した方がずっと楽。続く x.com/cocotan_0/stat…
メニューを開く
男性および女性それぞれ5名ずつ、計10名の身長をメジャーで測定した。 測定結果は以下のとおりであった。 男性の身長データ(cm) 170.2、175.4、180.1、169.8、171.2 女性の身長データ(cm) 165.2、160.7、157.8、158.2、155.9 t検定を行ったところ、t値が9.522と非常に大きく、対応するp値が0.000
メニューを開く
#統計 だから、2つのP値函数(もしくはその類似物)が近似的に一致することは、それぞれに対応する区間推定の結果が任意の水準1-αで近似的に一致することを意味しています。 github.com/genkuroki/publ… pic.twitter.com/BrB4TUuaMk
メニューを開く
#統計 通常のP値函数は信頼水準1-αの信頼区間が「P値≥αを満たすパラメータの範囲」となるような函数になっており、ベイズ版のP値函数の類似物は信用水準1-αの信用区間が「P値≥αを満たすパラメータの範囲」になるような函数として定義されます。 github.com/genkuroki/publ… pic.twitter.com/NSn0ZNY6V0
メニューを開く
#統計 蛇足の説明になってしまいますが、スコア法によるP値の構成法は最尤法に付随するP値の標準的な構成法の1つです。 グラフを見ればわかるように、シンプルなモデルにおける通常のP値函数はベイズ統計での事後分布とほぼ同じ情報を持っています。 x.com/makaishi2/stat… pic.twitter.com/XH05JVl9P9
返信先:@genkurokiご指摘ありがとうございます。途中経過を端折ったため誤解を招いたかもですが、モデルの前提は普通に二項分布で考えており、事後分布は次のグラフになります。… pic.twitter.com/XalJkMVPr1
メニューを開く

#統計 あと、確率の違いは 情報量 = - log₂ 確率 とおいて、情報量の差(単位はビット)で測ると誤解し難いです。 例えば、確率0.7(情報量0.5ビット)と確率0.3(情報量1.7ビット)の違いは1.2ビットしかない。これは小さな違いです。 P値の場合については ↓ biostatistics.ucdavis.edu/sites/g/files/… pic.twitter.com/OI6ivUBgUZ
メニューを開く
返信先:@Jimo0404他16人p値が約1万分の1ってどうなの? x.com/hkakeya/status…
昨日出演した宮沢先生のチャンネルで、オミクロン復帰変異株が意図的に拡散されたと考えられる根拠を示しました。データ数の多いBA.1とBA.1.1の13種類ずつの復帰変異を調べ、一般の変異株と比べ初期から非常に多くの州で同時検出されていることを確認。p値は約1万分の1です。 youtube.com/live/gWAU8msId…
メニューを開く
筑波大、掛谷先生、 オミクロン復帰変異株について、 本株はそもそも人工の可能性が極めて高い(ほぼ確実。確実と言うと、科学ではなくなるため言いません。) BA.1, BA.1.1は同時検出の観点等から、ほぼばらまかれたと言うことがわかってきました。 P値は10,000分の1です。 この意味わかりますよね? x.com/hkakeya/status…
昨日出演した宮沢先生のチャンネルで、オミクロン復帰変異株が意図的に拡散されたと考えられる根拠を示しました。データ数の多いBA.1とBA.1.1の13種類ずつの復帰変異を調べ、一般の変異株と比べ初期から非常に多くの州で同時検出されていることを確認。p値は約1万分の1です。 youtube.com/live/gWAU8msId…
メニューを開く
学部1年のときに統計学の授業はあったけど、p値を習ったことは見事に記憶にない… もうちょっと学年上がって臨床講義の一つとしてやった方が定着良かったんじゃないかな x.com/saguchitakemas…
百歩譲って数学のできる子供を医学部に入れるシステムは仕方ないとしても、せっかく数学の得意な医学生に大学でまともに統計学を教えないで、結果ほとんどがp値の概念を身につけないまま医師になるのはおかしいし、簡単に改善可能だと思う
メニューを開く
昨日出演した宮沢先生のチャンネルで、オミクロン復帰変異株が意図的に拡散されたと考えられる根拠を示しました。データ数の多いBA.1とBA.1.1の13種類ずつの復帰変異を調べ、一般の変異株と比べ初期から非常に多くの州で同時検出されていることを確認。p値は約1万分の1です。 youtube.com/live/gWAU8msId…
メニューを開く
マッキンゼーが成功するFP&Aについて解説。1) P値の明確化 2) モメンタムケースの提示 3) ベアケースの設定 4) マクロ経済前提の一貫性 5) インフレ率の詳細分解 6) 定期的なバックテストと修正。これらで企業の意思決定をサポートします。 #FP&A #財務計画 #ビジネス分析 buff.ly/3SeeMnN
メニューを開く
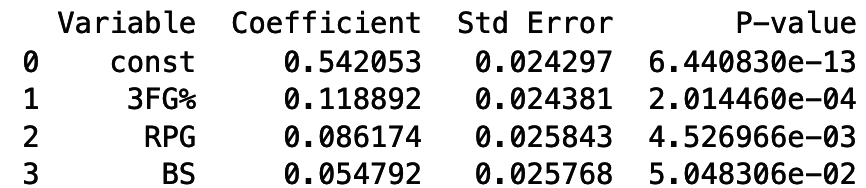
試合に勝つには何が重要か? B1リーグクラブの勝率を被説明変数、スタッツを説明変数にして重回帰分析からP値が有意なものに絞り込んだらこうなった。 RPG(平均リバウンド数)が有意なあたり、リバウンドを制するものが試合を制するが証明された?知らんけど。 pic.twitter.com/CtxAbuq6nH
メニューを開く
どこにもリプせずに単独で同じアンケート投げたら18%でした 自分の発言が届く範囲ってある程度浄化されてるのね 現時点でカイ二乗検定かけたらp値1.60×10^-7で統計的に異なる集団という結果になりました x.com/gsx2000rr/stat…
メニューを開く
返信先:@hellomitz3n=1ですね。 P-値が0.005になるまで症例集めてね。 医療は、統計学です。 n=1で問題提議していたら抗がん剤がいつまでも使えずに使えば治った可能性の高い人まで死んでしまいます。 お亡くなりになったのは残念だけど、それでは医学は進歩しません。
メニューを開く
ある効果量に対し尤度とP値が1つずつ付与されるので「尤度が正規分布であるなら、P値も正規分布である」が自明であり、黒木助教の様に余計な数式での証明など不要。シミュレーションも不要。 x.com/IEN_enjoy/stat… pic.twitter.com/Gm4aNh6g9l
帰無仮説が成り立つもとでp値が一様分布に従うことをちゃんと追ってみました。(離散の場合はややこしいので略) あとX~N(0,1)としたときに、帰無仮説が正しい場合(μ=0)と誤っている場合(μ=0.25)のp値の分布をシミュレーションしてみました。帰無仮説が成り立たない場合、p値は0に偏っています。 pic.twitter.com/E9iqqKXNko
メニューを開く
二項転帰での1対1写像(全単射)はフィッシャーの正確検定によるP値。 平均値の群間差 (MD) のような多項転帰での1対1写像(全単射)は Rubin 教授らによる総当り計算法(やシミュレーション法での近似)によるP値。 連続型(カイ二乗分布やt分布)は近似でしかない。 x.com/ueafam/status/…
可能であればフィッシャーの正確なP値を報告し基礎となる帰無仮説のランダム割り当て確率分布を表示する 2020 Marie-Abele Bind(助教授 @harvardmed/助教 @MGHbiostat)& Donald Rubin(名誉教授 @HarvardStats/教授 @Tsinghua_Uni/研究教授 @TempleUniv)@PNASNews pubmed.ncbi.nlm.nih.gov/32703808/
メニューを開く
被検者 200人を2個の群(100人 vs 100人)へランダム割当するような、臨床試験 (RCT) における試験終了時点での2個の群間差(群間比)のP値算出において、「母集団の分散が 同じ or 違う」という視点は存在しえない。なぜなら母集団は1個(N=200)しか存在しないので。
メニューを開く
tは数値なので、p=P(T≥t)も数値です。 数値のpが確率変数の1-F(T)に等しくなるはずがないです。 数値としてのP値のpと確率変数としてのP値 1-F(T) を厳密に区別しないとまずいです。 pvalue(t)=P(T≥t)=1-F(t)とおいて、pvalue(T)=1-F(T)を扱えば以上の問題を解消できます。 x.com/ien_enjoy/stat…
XやTと書くべきところをxやtと書いている箇所があり、指摘が入ったので、見直して修正verにしました。 一見小さな違いですが、確率変数と実現値の扱いは丁重であるべきで、きちんと推敲するべきでした。大変失礼しました。 そして自分では全然気づけなかったので、ご指摘ありがとうございます。 pic.twitter.com/SD503KxV8m x.com/genkuroki/stat…
メニューを開く
kyupin も『反精神医学』と差別用語を使用したが、彼はP値や仮説検定も信頼区間も何も知らない(ブログ検索したが1件もヒットしない)。kyupin は医学も精神医学も知らない。 x.com/ueafam/status/…
『これが、反精神医学の人々ならわからないでもないが、普通に指定医も持っている精神科医である。』 #kyupin ameblo.jp/kyupin/entry-1… x.com/ueafam/status/…
メニューを開く
返信先:@IEN_enjoyありがとうございます、なんとなくわかった気がします! 理解しやすくするためにまずは等号の時は、1-p0=F(t)になることまでは理解できた(p値の定義から自明)のですが、P(F(t))がいまいち解釈できず… 累積分布関数F(t)自体が確率という認識なので混乱しています😭
メニューを開く
A.1x2 の尤度関数 ← 離散型を投稿した。 B.1x2 のP値関数 ← 離散型を投稿した。 C.2x2 の尤度関数 ← 離散型を投稿したことが無い。 D.2x2 のP値関数 ← 離散型を投稿した。 x.com/ueafam/status/…
メニューを開く
「P値に基づく仮説検定」は、その観測値が稀な現象であるか否かは評価しておらず、5% 域に入ったらその仮説値は棄却する、というゲームでしかない。P=1.00 から P=0.95 の 5%(つまり山の高いところ)を棄却域に設定してもゲームは成立する。 x.com/kokonatsu2214/…
メニューを開く
「帰無仮説値が真値である場合に、P値が小さいと、稀な現象が起きた」というのは、正しくはない。 「モデル分布においては、稀な現象が起きたことになる」が、実際の分布形状はM字型で両外側ほど尤度が高いこともありえる。「P=1.00 付近は出現し難い」がありえる。 x.com/kokonatsu2214/…
メニューを開く
dp2[i]= iマス目からゴールまでの進み方 遷移はDAG それぞれNM*6+α回で済む 各Ci 1周目通る+2周目通る-1周目&2周目通る 2周とも通る時は周の間にdp1[N]いる F.結局2乗から落とせてない G.あー何でこれに1時間 Ai,xは座圧 ソート後更新配列B,更新箇所配列P 値の個数をセグ木に載せにぶたんでt=3はok ↓
メニューを開く
ぶっちした統計の授業確認してるけど ・帰無仮説対立仮説 ・棄却採択有意水準 ・p値 ・仮説検定 ・差の差検定 ・t検定 ・比率の検定 ・多重比較 ・第1種の過誤、第2種の過誤 を1回の授業で終わらせる教授と、それについていく学生バケモンでは(※文系)
メニューを開く
ぶっちした統計の授業確認してるけど ・帰無仮説対立仮説 ・棄却採択有意水準 ・p値 ・仮説検定 ・差の差検定 ・t検定 ・比率の検定 ・多重比較 を1回の授業で終わらせる教授と、それについていく学生バケモンでは(※文系)
メニューを開く
それは、完全にデタラメ。背景因子の話題だけでなく、P値や仮説検定や Null に関しても。支離滅裂な文章になってる。 『RCTのTable 1において真の群間差はnullであるため,有意であったとしても単にノイズをひろっているだけです.なので検定する意味がありません.』 x.com/Shuntarooo3/st…
返信先:@06Imc6zGsgclRsHそうです.RCTのTable 1において真の群間差はnullであるため,有意であったとしても単にノイズをひろっているだけです.なので検定する意味がありません.
メニューを開く

【統計まとめ】 ・パラ/ノンパラ ・回帰分析 についてまとめました! ↓さらに完全版では↓ ・帰無仮説 ・p値 ・第1種/第2種の過誤 についてもまとめました! ▼完全版の受け取り条件▼ ①この投稿を「いいね」と「リツイート」 ② リプ欄のLINEより1分アンケート(初回)… pic.twitter.com/3t2TsdNkbq
メニューを開く
「RCTのTable 1にP値付けちゃう」問題、腫瘍学領域の第3相試験を対象にした研究が去年出てました。その頻度は25%で、関連する要因も検討されていました。 pubmed.ncbi.nlm.nih.gov/37827064/
メニューを開く

手元のキラ0・アンテナ★1+要員*1の結果(来援率194/300)と、先ほどのAsyuraさんのキラ0・アンテナ★1+要員*2の結果(来援率202/300)を見様見真似のt検定に入れるとこんな感じであってるかな 来援率の有意差があるとはいえなさそう(両側検定のp値が95%有意となる有意水準0.05を上回る) pic.twitter.com/C6cB5JYKeK
人気ポスト
店長さん無理しないで欲しい
1960〜70年にかけて海外のカメラマンが撮った新宿歌舞伎町の写真の中にガラの悪い天童よしみさんがいる😂
復帰後くらいの…席替え前提な何か……
結婚してください😍
めちゃくちゃ円安やけどアメリカ行ってきた🇺🇸 ニューヨークのついで感覚でディズニー行ったけど、スターウォーズがレベチすぎて笑ってる。
ちょっとコンビニ行こうと支度してたらメチャクチャ悲しそうな顔されて外出できん😭😭😭
絶対にわかり合えなくて面白い
露出に反応したストーカー側の意見が じゃあ露出するなよって事なら 理性保てない男は家から出るな。だね 激アツな今露出にいちいち反応されてたら 全女子困ります。😮💨
なんかここまでくると怖い
?! これバレなかったのすごいね?!



