- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く

#統計 有意水準α=5%=信頼水準1-α=95%の信頼区間は 閾値αでデータの数値と相性が良いとみなされるパラメータδの範囲 になります。添付画像の橙色の横線が片側検定に対応する95%信頼区間です。 相性の良し悪しはP値≥αの成否で判断されるちいうルール。続く pic.twitter.com/fm7B8R5n6V
メニューを開く
#統計 P値全体 (P値関数)はnull P値と95%信頼区間の両方の情報を含むので、こんな感じのmemeも作れます。 1つ上のmemeは imgflip.com/memegenerator/… で作成。 以下は imgflip.com/memegenerator/… で作成。 pic.twitter.com/XGopLWqNYh
メニューを開く

#統計 検定仮説Δμ=μ_x - μ_y ≤ δ のP値 (nullとは限らないP値)は、 仮説 μ_x - μ_y ≤ δ とデータでの数値 x̅ - y̅ の相性の良さの指標の1つ だと解釈されます。 よく見る解説ではδ=0の場合のnull P値のみを扱うという不完全な説明をしています。これが酷い。続き pic.twitter.com/QY2vWxVt8k
メニューを開く

#統計 有意水準α=5%を使って、P値<αなら「相性は悪い」とP値≥αなら「相性は良い」と言い切ることにすると、 添付画像①の場合: 仮説μ_x - μ_y ≤ 0とデータでの数値x̅-y̅=1(小さめの値)の相性は良い。 添付画像②の場合: 仮説μ_x - μ_y ≤ 0とデータでの数値x̅-y̅=5(大きめの値)の相性は良い。 pic.twitter.com/eHhs5lYoOa
メニューを開く

#統計 検定仮説Δμ=μ_x - μ_y ≤ 0 のP値 (null P値と呼ぶ)は、 仮説 μ_x - μ_y ≤ 0 とデータでの数値 x̅ - y̅ の相性の良さの指標の1つ だと解釈されます。x̅ - y̅ が正の方向に大きくなればなるほど仮説 μ_x - μ_y ≤ 0 との相性は悪くなります。 添付画像のグラフでもそうなっています。続く pic.twitter.com/fMYSJbQOxe
メニューを開く

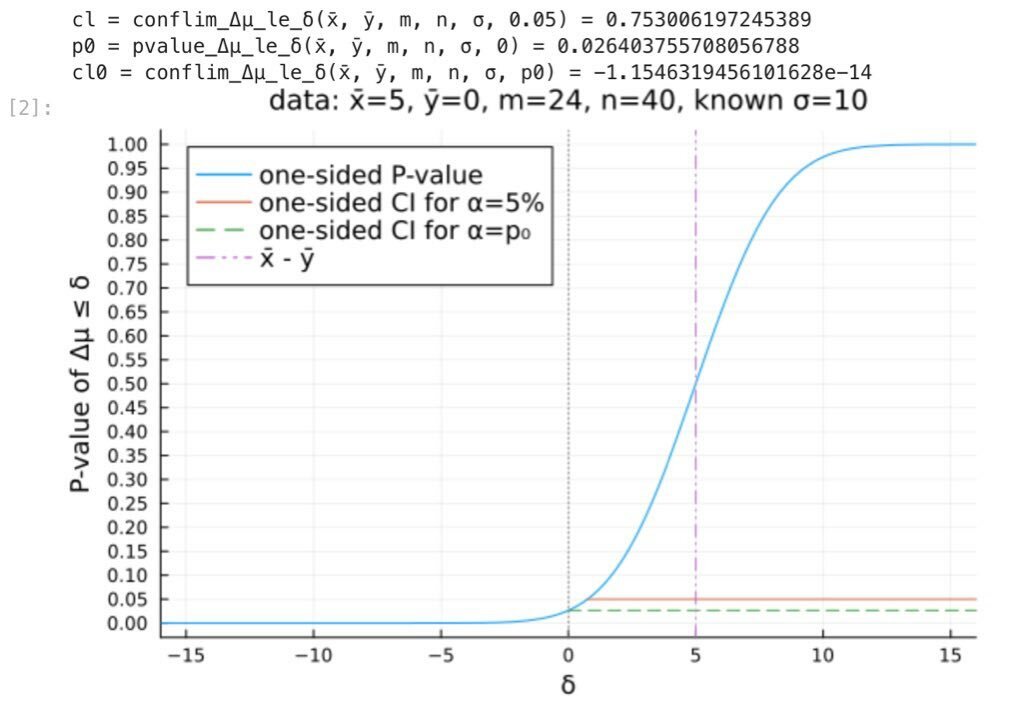
#統計 添付画像は既知の分散10²を持つ2つの正規母集団というモデルの設定での母平均に差Δμ=μ_x-μ_yに関する 帰無仮説Δμ≤δ (検定仮説と呼ぶ) 対立仮説Δμ>δ のP値のグラフ。 標本サイズはm=24, n=40. 添付画像①は表品平均の差がx̅-y̅=1の場合。 添付画像②は表品平均の差がx̅-y̅=5の場合。 続く pic.twitter.com/VUkj376NTT
メニューを開く
#統計 Neyman-PearsonのPearson氏も1955年に、「仮説検定は最終判定を与えない。しかし、道具として最終的な意思決定の形成を助ける」と言っています。 「P値<5%」のような条件単体で判定を下すのは誤りで、有益な情報の1つとして利用するのが正しい。 薬が効くかどうかの判定でも当然そうなります。 x.com/genkuroki/stat…
#統計 Pearson (1955)には NeymanとPearsonは「__最終的な__採択と棄却の話をしていない」し、「仮説検定が不可逆な採択の手続きを強制するべきだとは全然示唆していない」 とはっきり書いてあります。証拠提示終了! 戯画化されたNPについて騙る行為は滅びるべき! pic.twitter.com/4YR6Rw4Ec6
メニューを開く
#統計 一般に信頼水準1-αの信頼区間は「P値≥αとなるパラメータの値の範囲」になります。 帰無仮説Δμ:=μ₁-μ₂≤0のP値p₀はグラフではδ=0のP値です。P値はδについて単調増加なので、「P値≥p₀となるパラメータの値の範囲」は自明に0以上の実数全体になります。 自明! github.com/genkuroki/publ… pic.twitter.com/SK48oRIRJC
メニューを開く
#統計 以上の話を理解し易くするための計算例のグラフも作りました。 青線は片側P値のグラフ。 橙横線は片側95%信頼区間。 帰無仮説μ₁-μ₂≤0のP値p₀は緑横破線の高さで、緑横破線は片側の信頼水準1-p₀の信頼区間です。自明な理由で0以上の実数全体になる。 #Julia言語 github.com/genkuroki/publ… pic.twitter.com/b8wxxNKyh6
メニューを開く
#統計 続き。信頼区間の被覆確率1-αのαは標本の値によらずに決まっている定数です。P値p₀は標本の値の関数です。この辺の違いが全然考慮されていないように見える。 これは査読をされずに出版されたのでしょうか? pic.twitter.com/ClhM20PB5Q
メニューを開く
#統計 σは既知の設定。 μ₁とμ₂は母平均達なので固定された未知の数値です。 だから、μ₁-μ₂>0となる確率は1または0です。 帰無仮説μ₁-μ₂≤0のP値p₀は標本を取り直すごとに値がランダムに変わる確率変数とみなせます。「1-p₀の確率でいえる」の意味が不明になる。続く x.com/genkuroki/stat…
#統計 jstage.jst.go.jp/article/jjb/38… 柳川堯(2018) は信頼区間についても滅茶苦茶なことを書いています。 ↓ 【p値がp₀であるということは,µ₁−µ₂の信頼度1−p₀の信頼下限が正であること,つまりバラツキを考慮してもµ₁−µ₂>0であることが1−p₀の確率でいえるということである】 pic.twitter.com/0Er6nDd7av
メニューを開く
#統計 jstage.jst.go.jp/article/jjb/38… 柳川堯(2018) は信頼区間についても滅茶苦茶なことを書いています。 ↓ 【p値がp₀であるということは,µ₁−µ₂の信頼度1−p₀の信頼下限が正であること,つまりバラツキを考慮してもµ₁−µ₂>0であることが1−p₀の確率でいえるということである】 pic.twitter.com/0Er6nDd7av
メニューを開く
ブラウザだけで使える無料統計ソフト Reactive stat のサマリー表の作成 (Table One) をアップデートしました。 emuyn.net/stats/table_one 1x2 または 2x1 の表になった場合の p値の計算に、二項検定 (Binomial test) を行えるようにしました。
メニューを開く
返信先:@mazuisakeちゃんと読んでみました。尤度比は自然対数としてln(LR) = z(N – A) – 1/2(N^2 – A^2)で算出しており、P値を二値的ではなく連続的な尺度で分析していますね。既存のデータを次元を変えて分析しているだけなんでHARKingということにはならないかと💦medyで取り上げたいと思います。
メニューを開く
信頼係数1-p(pはp値)の信頼区間の下限は常に0をまたがず、nが大きくなっても信頼区間幅は一定らしい。 jstage.jst.go.jp/article/jjb/38… #iron勉強メモ
メニューを開く
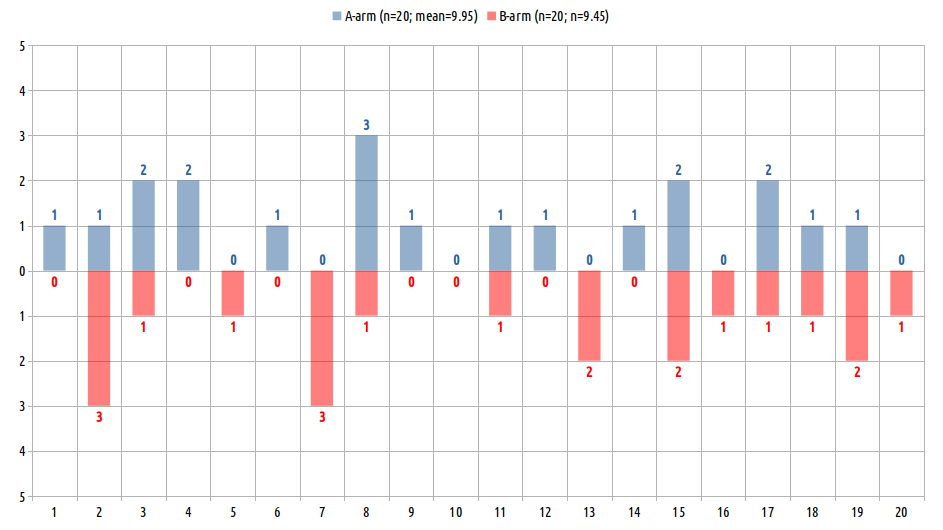
この例の母集団分布(帰無仮説 (Sharp Null)分布)は 1, 4, 3, 2, 1, 1, 3, 4, 1, 0, 2, 1, 2, 1, 4, 1, 3, 2, 3, 1 である。それを2つの群へランダム割当するシミュレーションを 100 万回とか試行して、平均値の群間差 (MD) をプロットすれば確率分布(尤度分布)ができあがり正確なP値を算出できる pic.twitter.com/Jt4Ti6E3Ji
メニューを開く
#統計 以下のリンク先の証明は本質的に、 (信頼水準1-αの信頼区間) = { a | (仮説θ=aのP値)≥α } のとき、 (信頼区間の被覆確率) = 1 - (P値のαエラー率) が成立していることを示しています。 信頼区間の被覆確率に感する説明は本質的にP値のαエラー率に関する説明と同じだということになります。 x.com/genkuroki/stat…
#統計 証明 (C0) ⇔ (a∈(信頼水準1-αの信頼区間)となる確率) ≈ 1-α ⇔ ((仮説θ=aのP値)≥αとなる確率) ≈ 1-α ⇔ ((仮説θ=aのP値)<αとなる確率) ≈ α ⇔ (P0) q.e.d.
メニューを開く
#統計 脱線しまくった。 P値について教えるときには、「違いはない」型のゼロ仮説単独の1つのP値のみを見せるのではなく、常に「違いはaである」の型の仮説達の無数のP値を見せるようにしたいものだと思います。 ゼロ仮説への異様なこだわりはnullismという名の病気の症状の1つです。「有意差病」 x.com/genkuroki/stat…
#統計 色々言っていますが、個人的にP値の解説において最も優先するべきだと思っていることは、ゼロ仮説θ=0のP値だけではなく、一般の仮説θ=a (aは任意の数値)のP値全体を考えること。 これは「もう〇〇はやめよう」(例「統計的有意と言うのはやめよう」)の型の提案と違ってプラス面しかない。
メニューを開く
#統計 母比率の「違い」では 「違い」の測り方が複数あること に触れざるを得ない。例えば、2つの母比率をp, qと書くとき、「違い」を測る指標として以下を選べる: * 差p - q * 比p/q * オッズ比 (p/(1-p))/(q/(1-q)) 現実の統計ソフトではゼロ仮説p=qのP値しか実装されていないことが多い。 x.com/genkuroki/stat…
#統計 2×2の分割表に関するχ²検定の実装のあるべき仕様は ①デフォルトでは連続性補正を一切適用しない。 ②オッズ比、リスク比、リスク差の信頼区間を計算してくれる。 ③オッズ比、リスク比、リスク差の値に関する検定仮説のP値を計算してくれる。 ④P値関数のグラフを作画してくれる。 x.com/genkuroki/stat…
メニューを開く
「平均値の群間差 (MD, SMD)」のP値を算出するには、t検定類は不要。中心極限定理の挙動を確認するためのシミュレーションを、疫学調査の実践現場でも同様に試行すれば良いだけ。この真実に、歴史上の生物統計学者や疫学者は1人も気づくことができなかった。 pic.twitter.com/hZQU33skA2
メニューを開く

🇮🇱 endotoxin💉⇒腸管から隣接する腸管腔へ脱出⇒腸重積⇒腸閉塞で手術必要に geoffpain.substack.com/p/intusseption… 🇮🇳 content.iospress.com/articles/inter… 腸重積の平均年齢が接種者205日で未接種者223日より僅か⬇️p値0.0026 接種後30日は次30日より腸重積⬆️92 対 63 p値0.009 未接種除外⇒3回目接種1~21日でrisk⬆️IRR2.47 pic.twitter.com/oUbOdDd0Yw x.com/sdgisan/status…
返信先:@funasejuku他1人母子手帳は日本弱体化ツール😡 この30年で乳幼児ワクチン激増😳 左 30年前:6種類 14回 右 現在: 14種類 36回 (ちなみに60年前も6種類) 本当に打った方がいいワクチンは🤔 #お母さんが未来を救う pic.twitter.com/1a35wY4Thd
メニューを開く
それだと「尤度は尤もらしさを意味してない」と力説してたのと矛盾する。 『例えば、P値が最大の1になるモデルのパラメータの値すなわちデータの数値と最も相性が良いモデルのパラメータの値はは点推定値だと解釈されます。』 [x.com/genkuroki/stat…]
メニューを開く
返信先:@toshizumi1225もし帰無仮説が「F(標本からのエフ)=1」(σ̂₁²=σ̂₂²)ですと例えばσ̂₁²=6,σ̂₂²=2なら(F分布やp値などをもちださなくても)F=6/2=3≠1よりこの帰無仮説が即時に("統計的な"検定をせずに)棄却されてしまいますよね
メニューを開く
#統計 「P値<α」に関わるしんどい説明は後回しにして、 データの数値とモデル+パラメータの値の設定の相性の良さの指標の1つ という安全なP値の解釈を先に説明してしまい、P値の解釈をはっきりさせておいた方が私は良いと思います。 そうすればASA声明準拠及びGreenland準拠になります。安全牌! x.com/genkuroki/stat…
#統計 データの数値とモデル(+パラメータの値の設定)の相性の良さ(compatibility)の指標の1つ というP値の解釈の仕方は、Sander Greenlandさん達が繰り返し論文を書いて普及させようとしている解釈でもあります。ASA声明の原則1にあるP値の解釈はそれと本質的に同じ。
メニューを開く
#統計 チェック項目1: P値が特定の統計モデルに依存して決まる値であることを強調しているか? ASA声明には「特定の統計モデルの下でデータの統計的要約値が観察された値以上に極端な値を取る確率」と、「特定の統計モデルの下に」と書いてあります。続く ASA声明 scholar.google.co.jp/scholar?cluste… より ↓ pic.twitter.com/UJJZq98DTV
メニューを開く
#統計 再度強調 P値とは何かについて (1) P値はデータの数値以上に極端な値がモデルの確率分布で生成される確率である という説明はできても、P値の解釈について、ASA声明にある (2) P値はデータの数値とモデルの相性の良さの程度を表す という説明を無視すると、誤解誘導的な解説になり易い。 x.com/genkuroki/stat…
#統計 P値についての適切な解説が出て来難い理由は、ASA声明 scholar.google.co.jp/scholar?cluste… の2の「P値とは何か?」とほぼ同じ説明はできるが、3の原則の1に書いてあるP値の解釈の仕方を無視する人が多いからだと思う。 P値の誤解は解釈で起こり易いので、原則の1を無視すると誤解誘導的な解説になりがち。 pic.twitter.com/On0Q4nbi7w
人気ポスト
この感じでお菓子出してくる人実家のお母さんぶりに見た
【速報】 タウシュベツ川橋梁湖側の手前から5個目のアーチが自然崩落しました。4枚目の写真は28日15時過ぎです。地震や4月の雪解け以外でこんな大規模崩落は初めてかもしれません。
コギ芋洗い
「病院行くよ」って言ったらビビりすぎて3頭身になってたの、今見てもよく分からん
私へ グレープフルーツ切って冷蔵庫で冷やしてあるよ、好きなときに食べてね 私より
ブックオフ普段の115倍くらいプラモある、確実に誰か死んだな
無断キャンセルのたびにこころがキュッと痛む。7月から事前決済システム導入のため、宿泊料を値上げさせていただきますm(_ _)m
この本の続きがあるかと聞いたら「ちょっと探しますわ…」と言われて足元が開いた 東京ってすごい
1960年代に「水曜どうでしょう」サイコロの旅があったら…という動画を本家さまと制作しました😊 気が狂うほどの長時間列車移動、拉致されたことを親に報告できる「電報チャンス」、一社提供ゆえの「スポンサーによる番組介入」など、見どころたくさんのバラエティ番組です! youtu.be/dWzqi3gjS98
【対策】救急車でコンビニ利用を容認へ、連続出動で昼食抜きの隊員多く 大阪・堺市 news.livedoor.com/article/detail… 駐車中の救急車に「次の出動に備えた水分と食事の摂取、トイレの利用にご理解をお願いいたします」と書かれたパネルを掲示する。市消防局は「市民の皆さんにはご理解いただきたい」と話す。



