- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く
取引先に出す文書に統計的な検定推定を載せるのは良いとして、p値やアスタリスクで1行で済む内容を、帰無仮説や対立仮説云々で3ページくらい掛けたのを見た日には、丁寧過ぎて貰った相手もアチャーとなっただろうなと思ったことはある。 分かっていないのに分かった振り。
メニューを開く
この例では、あるチャレンジ(例えば、宝くじやくじ引きなど)を24万5000回試みた結果、1等が8回当たったという状況が与えられています。これを統計的に評価するために、p値(pバリュー)を計算する方法を考えます。 ### 仮定 1. **帰無仮説 (H₀):**…
メニューを開く
#統計 P値が最大の1にならない回帰係数の値達には、データの数値への適合度が最大ではない回帰直線が対応しています。 最尤法でもP値を適切に定義することによって、適合度が最大でない回帰直線達も考えることができるようになります。そのことを利用して区間推定も可能になります。 続く x.com/ds_school_1/st…
こちらご指摘いただいたことをもとに修正させていただいたのですが、ベイズに詳しい方こちらの修正後の資料では違いを正確に表現できておりますでしょうか? pic.x.com/auhw3m8zfw x.com/DS_school_1/st…
メニューを開く
#統計 データの数値への回帰係数の適合度(最近の私は「相性の良さの程度」と表現することが多い)の指標の1つはP値と呼ばれており、最尤法で求めた回帰係数はデータの数値への適合度が最大なのでそのP値は1になります。 続く x.com/ds_school_1/st…
こちらご指摘いただいたことをもとに修正させていただいたのですが、ベイズに詳しい方こちらの修正後の資料では違いを正確に表現できておりますでしょうか? pic.x.com/auhw3m8zfw x.com/DS_school_1/st…
メニューを開く
統計学を使う学術研究は、基本的にはp値を0.05(5%)に設定するので、極端な話、20回に1回は間違えるものを正しいものとする。であるから、ワクチンなどのヒトに関わる研究の場合、統計手法を変えたり、対象者を変えたり、プラセボを置いたりして、信頼性を高める。しかし、100%安全は無理である。
メニューを開く
さてさて、試合終わったので このフレップ神話について3通りの解析をしました。 ①勝てない(負けor引き分け) ②勝たない(負けのみ) ③引き分けを除いた結果 いずれも有意差ありでした。 つまりフレップがいると… p値 ①0.00321 ②0.00777 ③0.00537 x.com/satorippi35/st…
メニューを開く
返信先:@genkuroki質問へのお返事ですが、以下のコードです。Wald法ではstrata.score のところが strata.wald で計算していて、正しい値が得られています。 # p値計算 calculate_p_value <- function(estimate, se) { if (se == 0) { if (estimate == 1) 1 else 0 # オッズ比とリスク比の場合 } else {…
メニューを開く

返信先:@PPubmed#統計 EMUYN広報さんに質問 添付画像①でのスコア法のP値はどのようにして計算していますか? 私はepiR::epi.2by2で計算したのだと解釈して添付画像②のように計算してみましたが、添付画像①のスコア法のP値が見当たりません。 私はepiRに失礼なことを間違って言ってしまったかもしれません。 pic.x.com/hx7ubalgqw x.com/ppubmed/status…
返信先:@genkurokiそうなんです。アプリの右側の クラウド R のコードを見ていただければわかりますが、下記(抜粋)のような記述にしています。epiR は計算法が複雑で、中でもリスク比だけは違う値が出るのです。他のp値も自分の実装とは異なる値が出ます。(それで自前の実装を諦めた) method は研究計画の設定ですが…
メニューを開く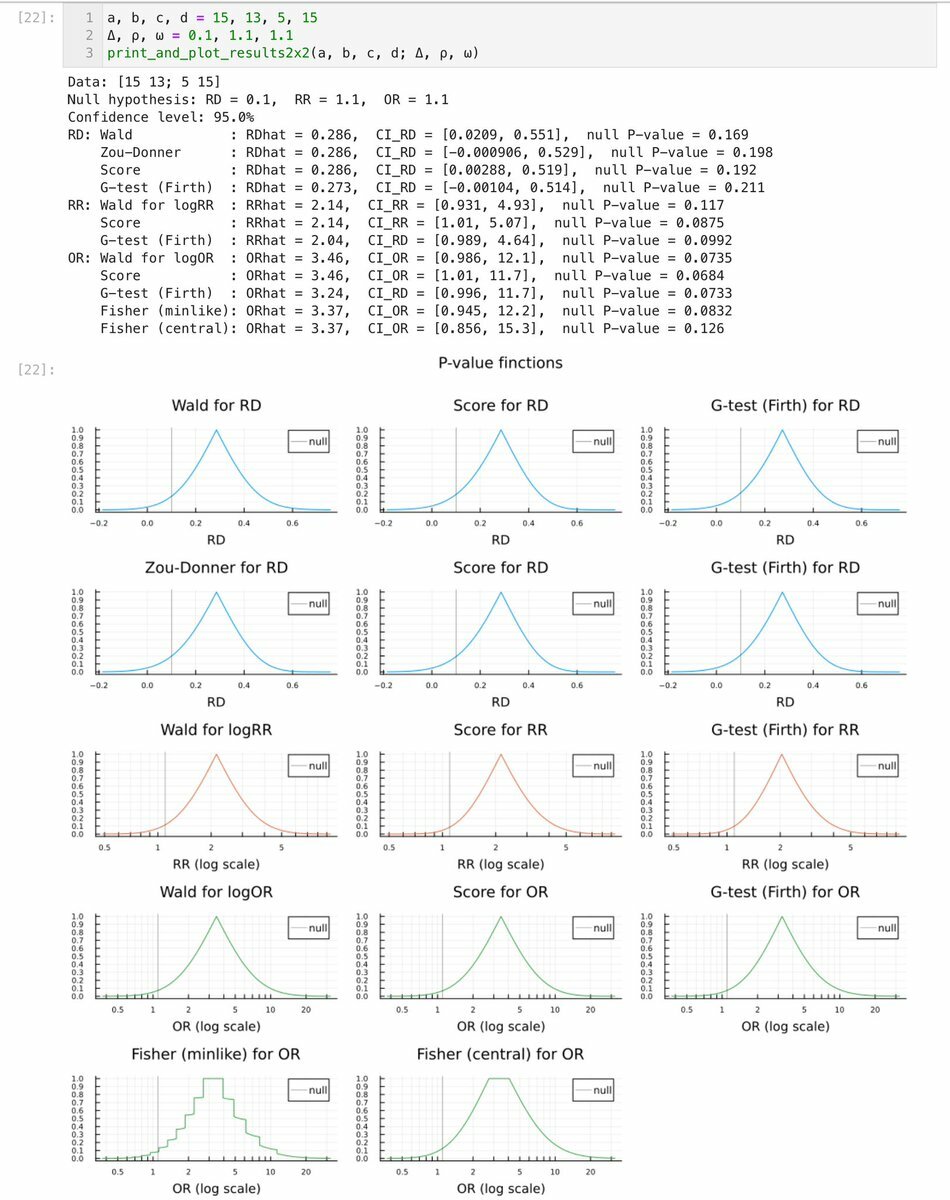

#統計 別スレッドは以下のリンク先から始まります。 EMUYN広報さんが実装したスコア法のP値関数と私が実装したスコア法のP値関数が一致するどうかも知りたいところ。 私の実装の場合 ↓ github.com/genkuroki/publ… それぞれRD=0.1, RR=1.1, OR=1.1という帰無仮説(検定仮説)のP値を計算しています。 ↓ pic.x.com/glbo1sbnhy x.com/ppubmed/status…
返信先:@genkurokiそうなんです。アプリの右側の クラウド R のコードを見ていただければわかりますが、下記(抜粋)のような記述にしています。epiR は計算法が複雑で、中でもリスク比だけは違う値が出るのです。他のp値も自分の実装とは異なる値が出ます。(それで自前の実装を諦めた) method は研究計画の設定ですが…
メニューを開く


返信先:@PPubmed#統計 私の数学的に素直な実装の計算結果(添付画像①②(2×2のデータが互いに転置の関係))と添付画像③を比較すると、適当に数字わせすると、信頼区間の数値は一致しています。 100(1-α)%信頼区間達(αを動かす)から逆にP値関数が得られるので、その意味では「本質的に同じ」だともみなせます。続く pic.x.com/h8lpququ0s
メニューを開く
#統計 例えばこれは酷いと思いました。 ckt-hanbai.co.jp/wp/wp-content/… 練習問題1の「出た回数の数値例」が非現実的でかつ(2)の「小数第3位までで答えなさい」が酷い。 練習問題2(2)も酷い。試しにnull P値を計算したら巨大な値に。 pic.x.com/rsymar2ynr
メニューを開く
Bigqueryで手軽にウェルチのT検定できるUDFを考えてる。 select t_test(data1_query,data2_query,有意水準) で、 統計量T、p値、有意水準、棄却判定結果 のテーブルを返す
メニューを開く

効果量のP値の信頼区間について、EXCELの計算式を追記しました。 ①平均値の差の検定の信頼区間を、プールした標準偏差で割ったものが、効果量の信頼区間 ②効果量のP値の信頼区間は、効果量の信頼区間の上側と下側に対して求めたP値(普通のP値は区間の平均値) data-science.tokyo/ed/edj1-1-3-4-… pic.x.com/tt3fuy3s5n
メニューを開く
返信先:@surinobaasan他2人二つの試験の有意差を計算しましたか? 4価単独では、ギリギリ有意差が出ないのですが、2価は単独で有意差あり、 この二つをメタ解析すると オッズ比5.4 95%信頼区間2.91〜 10 p値1.1× 10⁻⁷ I²検定0% 有意差ありですね。計算が間違えていたら教えてください。
メニューを開く
【新刊】2024年9月号『グルカゴン・GLP-1・GIPの創薬革命』が本日発行! 様々な代謝性疾患への有効性がみえてきたグルカゴン,GLP-1,GIP.急速に進む創薬研究について特集! ☆注目記事 ビッグデータ時代の医学系研究におけるp値 ↓目次・購入はコチラから yodosha.co.jp/jikkenigaku/bo…
メニューを開く
Ca/P値によると思います 当院の方針としては ①Calcimimetics(ウパシタ,パーサビブ,オルケディア)でしっかりとi-PTHを下げる ② ①でCa/Pも連動で下がるので、低Caに対して、CaCO3やVDRAで補充 ③低PTHで高P血症はテナパノル塩酸塩などを活用 x.com/ryu04196650ryu…
メニューを開く
#統計 ASA声明の原則1の解釈の仕方については以下のリンク先スレッドを参照。 ASA声明の原則1にはP値の正しい解釈の仕方が書いてあり、非常に重要です。ASA声明を引用する人は、以下のリンク先の注意に従って、原則1を引用するべきだと思います。 x.com/genkuroki/stat…
#統計 ASA声明 scholar.google.co.jp/scholar?cluste… の ❌P-values can indicate how incompatible the data are with a specified statistical model. を ⭕️P-values can indicate how compatible the observation data are with a specified statistical model. に訂正したい。その理由に続く pic.x.com/ioiiq0kve8 x.com/genkuroki/stat…
メニューを開く
#統計 補足 ベイズ信用区間の場合に限らず、任意の区間推定法には aが閾値100(1-α)%での区間推定の結果の端点のとき (仮説θ=aのP値) = α によってP値を定義できます。例えば、ETI版信用区間には (仮説θ=aのP値) = (事後分布でのθ≤aの確率とθ≥aの確率の小さい方の2倍) が対応している。続く x.com/genkuroki/stat…
#統計 補足。平坦事前分布の場合の結果でのベイズ的なP値の類似物の値は33%と非常に高く、通常のP値(スコア法)は37%とそれに近い値になります(数学的には必然の近似)。 こういう場合に「わずかの差で~新人Aが優秀」(AはグラフのX側)と安易に言うのはとてもまずいです。続く github.com/genkuroki/publ… pic.x.com/pean5v97ww x.com/genkuroki/stat…
メニューを開く
相関係数の検定を、表に加えました。 「従来からある相関係数の検定は、計算した相関係数の確からしさを表す」という位置付けにしています。 相関性自体についての検定は、P値として、 「1 - 相関係数の2乗」 を提案しています。 data-science.tokyo/ed/edj1-1-3-5.… pic.x.com/wknfevplgi
メニューを開く
#統計 その場合には添付画像のような方法を使います。 ルーレット1,2をそれぞれm,n回回したときに出た当たりの回数a,cから、ルーレット1,2での当たりが出る確率p,qの比p/qの推定をP値を使って行う方法の1つ。 対数リスク比に関するWald型P値関数。 pic.x.com/kjsj8ixgjc
メニューを開く
動画中の話 ・世界で一番論文捏造してる研究者はぶっちぎり1位で日本人 ・凡ミスでスプレッドシート選択漏れ、偏った結果が出たが気付かない論文 ・白いマウスを黒いマジックで塗って皮膚移植成功論文 ・STAP細胞左右反転画像 ・p値ハッキング ・実は再現実験実はあんまりされない
メニューを開く
#統計 P値関数は別に新しい概念ではない。当たる確率pの値に関する仮説を固定せずに動かして考えるだけ。 P値関数については、最初に1つ上の投稿で定義した最も易しいP値関数のグラフ(横軸はp、縦軸はP値)のグラフをコンピュータで描いてみるべき。 グラフのプロットの仕方の学習コストは結構高い。 pic.x.com/5ktvwxqlnh
メニューを開く
#統計 P値関数の易しい例は、二項分布の正規分布近似で構成されたP値関数。定義: データの数値「n回中x回当たり」と検定仮説「当たる確率はpである」のP値は 標準正規分布に従う確率変数の絶対値が|x-np|/√(np(1-p))以上になる確率。 与えられたx,nについて、pを動かしてP値のグラフを描けば良い。 pic.x.com/9ldcvhmtxj x.com/genkuroki/stat…
#統計 事後分布での片側確率の2倍は等踞版信用区間を区間推定法とみなしたときのP値に一致します。 任意の区間推定法からP値が逆に定義される。p=p₀が100(1-α)%区間に含まれないようなαの下限をp=p₀のP値と定義すればよい。 HDI版信頼区間に対応するP値関数との比較 ↓ github.com/genkuroki/publ… pic.x.com/svcguevaro
人気ポスト
このお写真、私密かにお気に入りなんです(*˘︶˘*).。.:*♡
↓ウインナーの試食販売って絶対こうならない?
170万円でボロ戸建てを買って約4ヶ月。週末にコツコツとDIYした結果がこちら
また...4回目って事実はもう嫌だ
これ塗っとけば大丈夫‼️ってなってた時代恐ろし
泊まったホテルのウェルカムアイテムがサングラスだった😎二人とも喜んでつけてて超きゃわわわだった💜
「かっこいいお写真撮るね!」って言ったら、足組みポーズ🥺☄️ 大興奮する私に笑いながらも、こうだよ♪って足を組んで見せてくれるプーしゃん、すき………すき………(重)
娘が本日台湾の大学へ入学の為旅立ちました。NCTを、ロンジュンを、クンを好きになって「中国語が話せる人になりたい」と進路を急に変えた高2の冬。母としては寂しい気持ちをグッと抑えつつ送り出しました。娘にとってNCTは、夢に向かって前に進む為の大切な宝物であり励みです。 娘よ…頑張れ!
ダイソーに売ってたグリッターのりをクリアパーツの裏に塗ってプラフスキー粒子の貯蔵を再現してみたよ
ポテトフライ頼んだのですが、僕の滑舌が悪すぎて手取川が到着しました。




