- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く
ASA声明的な「P値はデータの数値以上に極端な値がモデル内で生じる確率」のような説明だけをして、ASA声明原則1の「P値はデータの数値とモデルがどの程度compatibleであるかを表す」の方を引用しない人は、ASA声明で指摘されているP値に関する理解度の低さを認識できていない人である可能性が高い。 x.com/genkuroki/stat…
返信先:@abonst1009他1人注意: ASA声明に原則1を「P値はデータの数値と特定の統計モデルがどの程度compatibleであるかを表す」と訳しました。原文では"how incompatible"になっています。P値が大きい方がよりcompatibleなので"in-"を削除しました。P値とcompatibilityの程度の対応を大小関係を保つように翻訳したかった。
メニューを開く
返信先:@abonst1009他1人#統計 P値の計算や信頼区間の導出は一時的に現実のことは忘れてモデル内で行うことになるのだと承知していれば、 二項分布モデルBinomial(n, p)の中での標準誤差は√(p(1-p)/n)であることが分かっている という考え方でP値の計算や信頼区間の導出を行うことも当たり前の話になります。
メニューを開く
返信先:@abonst1009他1人#統計 P値や信頼区間と現実の直接的関係を完全に断つことは、ASA声明を理解するときには重要なポイントになります。 ASA声明原則1の「P値はデータとモデルがどの程度compatibleかを表す」という説明は、実質的に「おまえらみんな、P値についてまるっきり理解していないぞ」と言っているに等しい。
メニューを開く
返信先:@abonst1009他1人注意: ASA声明に原則1を「P値はデータの数値と特定の統計モデルがどの程度compatibleであるかを表す」と訳しました。原文では"how incompatible"になっています。P値が大きい方がよりcompatibleなので"in-"を削除しました。P値とcompatibilityの程度の対応を大小関係を保つように翻訳したかった。
メニューを開く
返信先:@abonst1009他1人そこを理解できていないと、「P値はデータの数値と特定の統計モデルがどの程度compatibleであるかを表す」というASA声明の原則1も理解できなくなります。 信頼区間はP値≥αとなるモデルのパラメータの値の範囲なので、ASA声明の原則1に従って解釈されます。
メニューを開く
返信先:@abonst1009他1人#統計 母比率に関するP値の計算や信頼区間の導出で使われる標準誤差は、二項分布モデルk~Binomial(n, p)内におけるp̂=k/nの標準偏差のことであり、√(p(1-p)/n)であることがモデルの設定によって分かっているものです。 これと現実の母集団での未知の母比率は無関係。 現実とモデルの混同はアウト。
メニューを開く

#統計 #julialang 昨日の続きです。 まず,黒木玄さん @genkuroki からコメントいただいた WaldとWilsonのP値関数を定義して,グラフを書いてみました。 (1/n) pic.twitter.com/Dh8zTgHdHk
メニューを開く
#統計 高校数学Bの教科書に出て来る信頼区間はWald法による信頼区間で、それを与えるP値関数は p̂ = k/n 2ccdf(Normal(), abs(p̂ - p) / √(p̂*(1-p̂)/n)) になります。WilsonのスコアP値関数は p̂ = k/n 2ccdf(Normal(), abs(p̂ - p) / √(p*(1-p)/n)) で素直で精度が高いのはWilsonの方。 x.com/dannchu/status…
#統計 #julialang 高校数学Bの教科書に出てくる信頼区間は,NLsolve.jl,Wilsonの信頼区間と比べて,からかなりずれてしまいました。 これだけずれてしまうと,高校の教科書で求めているものがちょっと不安になります。 (7/n, n=7 おわり) pic.twitter.com/zkMoSkI4j6
メニューを開く
#統計 #julialang 黒木玄さん @genkuroki のポストを参考にP値関数について考えてみることにしました。 二項分布B(n,p)を正規分布N(np,npq)に近似し, np-|np-k| 回以下 または np+|np-k| 回以上である確率を P値関数 pvalue_f(k,p,n) とする。 (1/n) pic.twitter.com/zLqjMjvyHb
メニューを開く
この手の予測で非常に懸念するのは、p値(確定範囲)をどれくらい取っているのか?が不明確であるのと、被予測者つまり生徒から見ればN=1なので確率的なたまたま排除されてしまうと不当な排斥が一生続いていまうことである x.com/toyokeizai_edu…
メニューを開く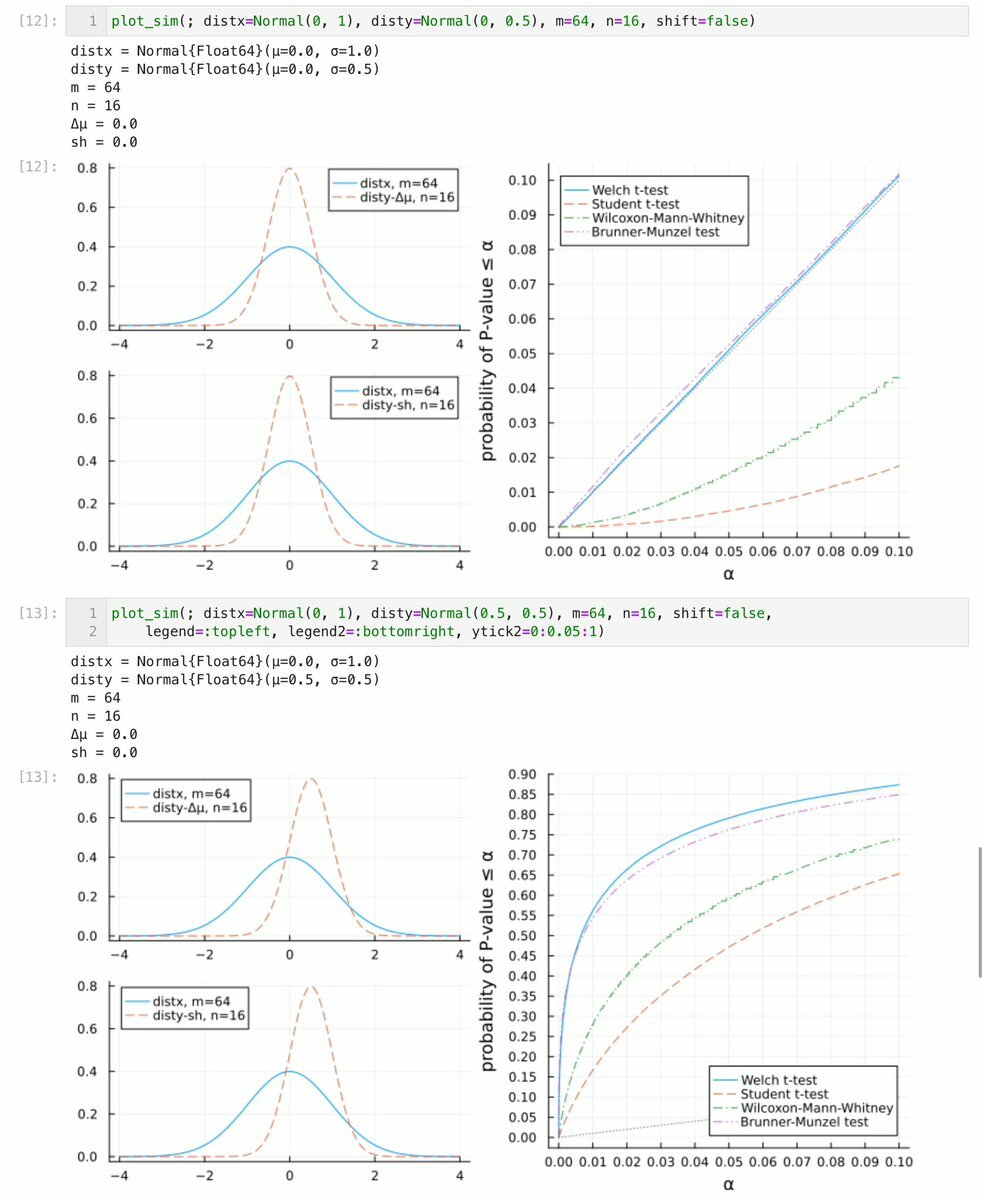

#統計 2つの母平均が等しい場合と比較すれば納得できると思います。 Studentのt検定は母分散が大きい側の標本サイズが大きいと、P値<αとなる確率は小さめになり(添付画像①)、母分散が小さい側の標本サイズが大きいと、P値<αとなる確率は大きめになります(添付画像②)。 github.com/genkuroki/publ… pic.twitter.com/BWpTTAe9sA x.com/tsakai_psych/s…
面白いのが、一枚目1行1列のn1:n2 = 1:0.25(64:16)条件 サンプルサイズが小さい群のSDが小さいとき(左図)はWelchのp値が小さくなりがちなのに、 反対にSDが大きいとき(右図)はStudentの方がp値が小さくなりがち(それでもp < .05は8割いってない) pic.twitter.com/i9Gd1YWu4z
メニューを開く


面白いのが、一枚目1行1列のn1:n2 = 1:0.25(64:16)条件 サンプルサイズが小さい群のSDが小さいとき(左図)はWelchのp値が小さくなりがちなのに、 反対にSDが大きいとき(右図)はStudentの方がp値が小さくなりがち(それでもp < .05は8割いってない) pic.twitter.com/i9Gd1YWu4z
メニューを開く

📢歴代の洋楽ヒット曲タイトルをプロンプトにして、ミドジャでイラストを生成してみた♪① 🧙♂️ タイトル(オリジナル) --ar 5:7 --s 1000 --p 実際のプロンプトはALTで🫣 みんなの --p値で、どれくらい変わるんだろうな~🧐ワクワク♪ PS「誰の曲?」って質問は禁止! 自分でググってね🤭 pic.twitter.com/LhnOxdj0r1
メニューを開く
#統計 P値全体 (P値関数)はnull P値と95%信頼区間の両方の情報を含むので、こんな感じのmemeも作れます。 1つ上のmemeは imgflip.com/memegenerator/… で作成。 以下は imgflip.com/memegenerator/… で作成。 pic.twitter.com/XGopLWqNYh
メニューを開く

#統計 検定仮説Δμ=μ_x - μ_y ≤ δ のP値 (nullとは限らないP値)は、 仮説 μ_x - μ_y ≤ δ とデータでの数値 x̅ - y̅ の相性の良さの指標の1つ だと解釈されます。 よく見る解説ではδ=0の場合のnull P値のみを扱うという不完全な説明をしています。これが酷い。続き pic.twitter.com/QY2vWxVt8k
メニューを開く
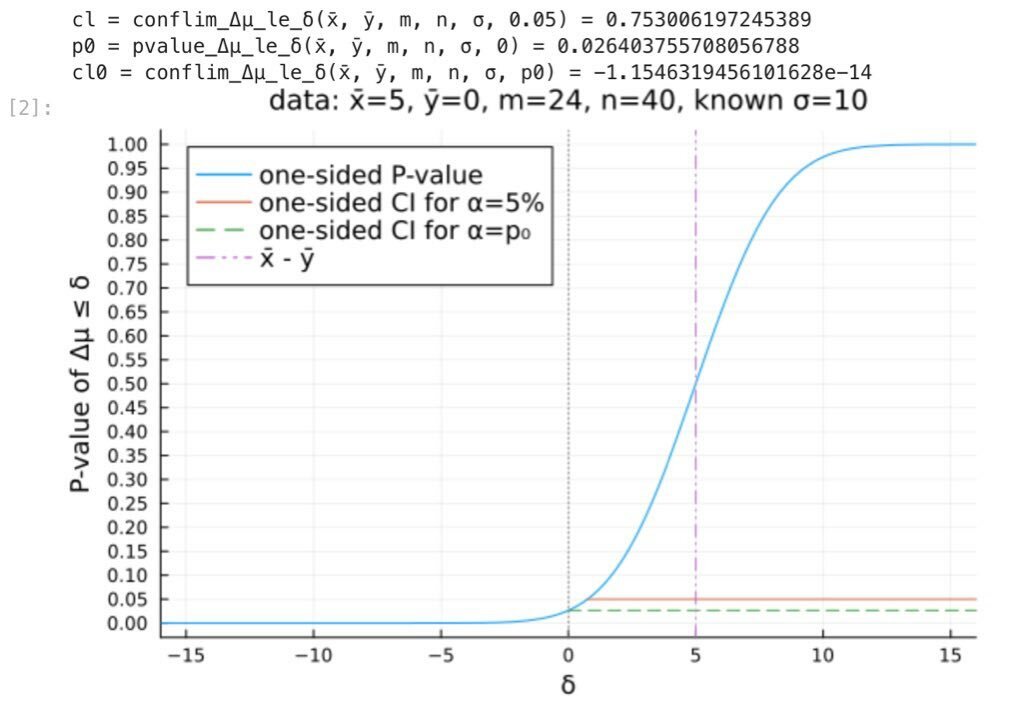
#統計 有意水準α=5%=信頼水準1-α=95%の信頼区間は 閾値αでデータの数値と相性が良いとみなされるパラメータδの範囲 になります。添付画像の橙色の横線が片側検定に対応する95%信頼区間です。 相性の良し悪しはP値≥αの成否で判断されるちいうルール。続く pic.twitter.com/fm7B8R5n6V
メニューを開く

#統計 有意水準α=5%を使って、P値<αなら「相性は悪い」とP値≥αなら「相性は良い」と言い切ることにすると、 添付画像①の場合: 仮説μ_x - μ_y ≤ 0とデータでの数値x̅-y̅=1(小さめの値)の相性は良い。 添付画像②の場合: 仮説μ_x - μ_y ≤ 0とデータでの数値x̅-y̅=5(大きめの値)の相性は良い。 pic.twitter.com/eHhs5lYoOa
メニューを開く

#統計 検定仮説Δμ=μ_x - μ_y ≤ 0 のP値 (null P値と呼ぶ)は、 仮説 μ_x - μ_y ≤ 0 とデータでの数値 x̅ - y̅ の相性の良さの指標の1つ だと解釈されます。x̅ - y̅ が正の方向に大きくなればなるほど仮説 μ_x - μ_y ≤ 0 との相性は悪くなります。 添付画像のグラフでもそうなっています。続く pic.twitter.com/fMYSJbQOxe
メニューを開く

#統計 添付画像は既知の分散10²を持つ2つの正規母集団というモデルの設定での母平均に差Δμ=μ_x-μ_yに関する 帰無仮説Δμ≤δ (検定仮説と呼ぶ) 対立仮説Δμ>δ のP値のグラフ。 標本サイズはm=24, n=40. 添付画像①は表品平均の差がx̅-y̅=1の場合。 添付画像②は表品平均の差がx̅-y̅=5の場合。 続く pic.twitter.com/VUkj376NTT
メニューを開く
#統計 Neyman-PearsonのPearson氏も1955年に、「仮説検定は最終判定を与えない。しかし、道具として最終的な意思決定の形成を助ける」と言っています。 「P値<5%」のような条件単体で判定を下すのは誤りで、有益な情報の1つとして利用するのが正しい。 薬が効くかどうかの判定でも当然そうなります。 x.com/genkuroki/stat…
#統計 Pearson (1955)には NeymanとPearsonは「__最終的な__採択と棄却の話をしていない」し、「仮説検定が不可逆な採択の手続きを強制するべきだとは全然示唆していない」 とはっきり書いてあります。証拠提示終了! 戯画化されたNPについて騙る行為は滅びるべき! pic.twitter.com/4YR6Rw4Ec6
メニューを開く
#統計 一般に信頼水準1-αの信頼区間は「P値≥αとなるパラメータの値の範囲」になります。 帰無仮説Δμ:=μ₁-μ₂≤0のP値p₀はグラフではδ=0のP値です。P値はδについて単調増加なので、「P値≥p₀となるパラメータの値の範囲」は自明に0以上の実数全体になります。 自明! github.com/genkuroki/publ… pic.twitter.com/SK48oRIRJC
メニューを開く
#統計 以上の話を理解し易くするための計算例のグラフも作りました。 青線は片側P値のグラフ。 橙横線は片側95%信頼区間。 帰無仮説μ₁-μ₂≤0のP値p₀は緑横破線の高さで、緑横破線は片側の信頼水準1-p₀の信頼区間です。自明な理由で0以上の実数全体になる。 #Julia言語 github.com/genkuroki/publ… pic.twitter.com/b8wxxNKyh6
メニューを開く
#統計 続き。信頼区間の被覆確率1-αのαは標本の値によらずに決まっている定数です。P値p₀は標本の値の関数です。この辺の違いが全然考慮されていないように見える。 これは査読をされずに出版されたのでしょうか? pic.twitter.com/ClhM20PB5Q
メニューを開く
#統計 σは既知の設定。 μ₁とμ₂は母平均達なので固定された未知の数値です。 だから、μ₁-μ₂>0となる確率は1または0です。 帰無仮説μ₁-μ₂≤0のP値p₀は標本を取り直すごとに値がランダムに変わる確率変数とみなせます。「1-p₀の確率でいえる」の意味が不明になる。続く x.com/genkuroki/stat…
#統計 jstage.jst.go.jp/article/jjb/38… 柳川堯(2018) は信頼区間についても滅茶苦茶なことを書いています。 ↓ 【p値がp₀であるということは,µ₁−µ₂の信頼度1−p₀の信頼下限が正であること,つまりバラツキを考慮してもµ₁−µ₂>0であることが1−p₀の確率でいえるということである】 pic.twitter.com/0Er6nDd7av
メニューを開く
#統計 jstage.jst.go.jp/article/jjb/38… 柳川堯(2018) は信頼区間についても滅茶苦茶なことを書いています。 ↓ 【p値がp₀であるということは,µ₁−µ₂の信頼度1−p₀の信頼下限が正であること,つまりバラツキを考慮してもµ₁−µ₂>0であることが1−p₀の確率でいえるということである】 pic.twitter.com/0Er6nDd7av
メニューを開く
ブラウザだけで使える無料統計ソフト Reactive stat のサマリー表の作成 (Table One) をアップデートしました。 emuyn.net/stats/table_one 1x2 または 2x1 の表になった場合の p値の計算に、二項検定 (Binomial test) を行えるようにしました。
メニューを開く
返信先:@mazuisakeちゃんと読んでみました。尤度比は自然対数としてln(LR) = z(N – A) – 1/2(N^2 – A^2)で算出しており、P値を二値的ではなく連続的な尺度で分析していますね。既存のデータを次元を変えて分析しているだけなんでHARKingということにはならないかと💦medyで取り上げたいと思います。
メニューを開く
信頼係数1-p(pはp値)の信頼区間の下限は常に0をまたがず、nが大きくなっても信頼区間幅は一定らしい。 jstage.jst.go.jp/article/jjb/38… #iron勉強メモ
メニューを開く
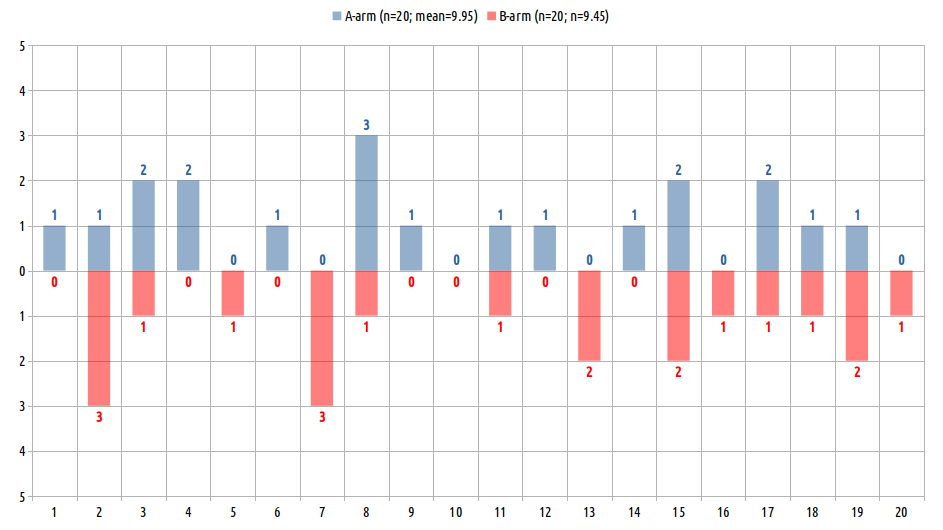
この例の母集団分布(帰無仮説 (Sharp Null)分布)は 1, 4, 3, 2, 1, 1, 3, 4, 1, 0, 2, 1, 2, 1, 4, 1, 3, 2, 3, 1 である。それを2つの群へランダム割当するシミュレーションを 100 万回とか試行して、平均値の群間差 (MD) をプロットすれば確率分布(尤度分布)ができあがり正確なP値を算出できる pic.twitter.com/Jt4Ti6E3Ji
メニューを開く
#統計 以下のリンク先の証明は本質的に、 (信頼水準1-αの信頼区間) = { a | (仮説θ=aのP値)≥α } のとき、 (信頼区間の被覆確率) = 1 - (P値のαエラー率) が成立していることを示しています。 信頼区間の被覆確率に感する説明は本質的にP値のαエラー率に関する説明と同じだということになります。 x.com/genkuroki/stat…
#統計 証明 (C0) ⇔ (a∈(信頼水準1-αの信頼区間)となる確率) ≈ 1-α ⇔ ((仮説θ=aのP値)≥αとなる確率) ≈ 1-α ⇔ ((仮説θ=aのP値)<αとなる確率) ≈ α ⇔ (P0) q.e.d.
メニューを開く
#統計 脱線しまくった。 P値について教えるときには、「違いはない」型のゼロ仮説単独の1つのP値のみを見せるのではなく、常に「違いはaである」の型の仮説達の無数のP値を見せるようにしたいものだと思います。 ゼロ仮説への異様なこだわりはnullismという名の病気の症状の1つです。「有意差病」 x.com/genkuroki/stat…
#統計 色々言っていますが、個人的にP値の解説において最も優先するべきだと思っていることは、ゼロ仮説θ=0のP値だけではなく、一般の仮説θ=a (aは任意の数値)のP値全体を考えること。 これは「もう〇〇はやめよう」(例「統計的有意と言うのはやめよう」)の型の提案と違ってプラス面しかない。
人気ポスト
長女が産まれた時にお祝いにもらった離乳食用のマッシャー、普通の調理でも重宝してずっと使っていたのですが、本日ゆで卵を潰した時にボキっとやってしまった。19年ありがとうな!!
着てると高確率で「どこの?」って聞かれるシャツ。一癖あるぽこぽこ生地、溶けるような肌触り、計算し尽くされたシルエット…これが4000円台なのやばい
義母が新紙幣でとんでもない神引きしてる これ確率ヤバそう
左 欲しかったやつ 右 親が買ってきたやつ
一万円の価値が半額になってるのかと思うくらいのクオリティ #新紙幣
銅のブレスレット今日届きました。付けた瞬間から左手示指から環指までの痺れが半分以下に!なんだこれ!時間が経つに連れ更に痺れが弱くなった。なんだこれ🤗
友達のノートまじかっけー
「オレンジジュースとリンゴジュースを凍らせたやつで白ワインを飲めば実質サングリアになるのでは?」と思ってやってみました。最強です。美味いしキンッキンに冷えるし氷が溶けるほどむしろ濃くなる。
買い物して出たら隣の15が見事なまでに 普段の足!乗りっぱなし!希少価値とか知らん! っていう具合でこのご時世ある意味新鮮だったので思わず撮ってしまった
テレビでYouTubeなんか見るもんじゃないな



