- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く
経験的な話とモデル的な話。 おいらとしてはモデル的(イデア的というべきか?)に話をするのが適切というのが現在の結論。 経験的な話は記述統計ではないのかと。 x.com/kaoru6/status/…
メニューを開く
Pythonデータ分析入門編に新講座追加 | 初心者でも記述統計量を理解できる - paiza times IT企業技術ブログ等アンテナより paiza.hatenablog.com/entry/2024/06/…
メニューを開く
返信先:@color_ed_flower(記述統計量はsummary()や、 library(psych) describe() で出せるってインターネット君が教えてくれましたがどうでしょう…?)
メニューを開く
統計学エアプだけど、セイバーメトリクスって記述統計みたいな面が強いので、そこで出てくる数字や指標もほとんどは予測的なものでなく説明的なものになる、ということはないんだろうか (説明的な指標でも予測に有効に使えることがあるのはさておき)
メニューを開く
次回のJASP大型アップデートに向けて、翻訳箇所のアップデートを行いました! 今回、特に注力したのはデフォルトとされている記述統計から因子分析機能のUI部分を重点的に翻訳&修正しました。次回のアップデートをご期待ください! 今後も引き続き翻訳を進めますが、要望、修正あれば教えてください🌟
メニューを開く
おはようございます.本日は1限に看護1年の統計の基礎です.量的2変数の記述統計の話をするついでに,相関関係があるからといって,因果関係があると思うなよ,という話をしたいと思います.先輩たちは覚えてますかね? デブほど頭がいいという子どもの話を.
メニューを開く

論文の査読,記述統計の表みて計算したら100%にならなかったり文章内の数字と違ってたりした場合一個一個再計算したり確認してお返ししますか,それともこの時点で見直しを依頼しますか?いい研究だけど数字は大事だからなぁ #論文査読 #レビュワー #学術誌 pic.twitter.com/W2Wv7OhmSm
メニューを開く
メニューを開く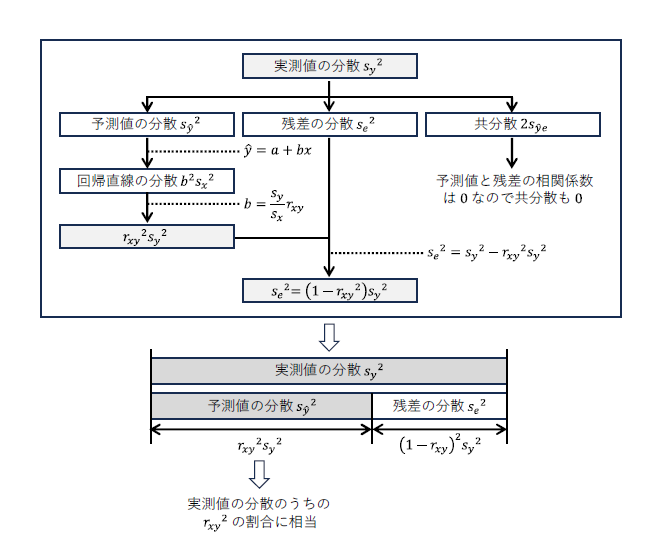

*記述統計* こちらの最小二乗法による回帰直線についての内容は画像のように整理しておくとよさそうです。最小二乗法のキーワードは「分解」かもしれません。 pic.twitter.com/UWd5tEfHY6
*記述統計* x+yの分散=x分散+y分散+2*xとyの共分散。 このxを回帰直線の予測値、yを残差と置き換えると、予測値と残差の和(つまり実測値)の分散=予測値分散+残差分散+2*予測値と残差の共分散、となります。 最小二乗法による回帰直線の予測値と残差の共分散は0なので(略)
メニューを開く
記述統計・確率統計まで完了。 ちょうど半分消化。公式暗記度は40-50%くらい。 ここからは、ここまでの知識を活用する内容とのことで少し楽になるとのこと。本当かな('Д') ■統計検定2級 ①Udemy対策講座 37(+6)/72 (52%) ②公式問題集 0/210 ➂模擬試験(過去1回分) 0/1
メニューを開く
記述統計の解釈について、1966-79年生まれの幸福度が最も低いということだが、論者が「肉体の衰え云々」などきちんとした要因分析を伴わない解釈を述べるのをマスコミが丸写しに述べるのは問題だ。就職氷河期経験者(1970-1982年生まれ)と大きく重なる。偶然ではあるまい。 mainichi.jp/articles/20240…
メニューを開く
*記述統計* x+yの分散=x分散+y分散+2*xとyの共分散。 このxを回帰直線の予測値、yを残差と置き換えると、予測値と残差の和(つまり実測値)の分散=予測値分散+残差分散+2*予測値と残差の共分散、となります。 最小二乗法による回帰直線の予測値と残差の共分散は0なので(略) pic.twitter.com/nYpzc9IhmX
メニューを開く


【第5回週例会】 本日の週例会は統計セクションでした!得られたデータを数値で要約する記述統計量をRstudioを使って算出しました! ↓キソケンFacebook↓ facebook.com/letkisoken pic.twitter.com/rK1TtpT8B8
メニューを開く
*記述統計* 2級のPBT最後の試験(2021年6月試験)の功績の1つは、あれを出題されると今後教える側が回帰直線の切片と傾きの式について「暗記でOK」と軽々しく言えなくなったことではないでしょうか。少なくとも導出までのプロセスは紹介せざるを得ないと考えます。 pic.twitter.com/L4lKhOT6Ii
メニューを開く
【質問】Excelを使った統計学のテキストで、「まずこのデータ(n=100)の特徴をつかみたいです。記述統計量をまとめてみよう」みたいな例題で、標準偏差をSTDEV.S関数で出していて、この場合ならSTDEV.P関数を使う(n-1じゃなくてnで割る)べきじゃないかと思うんだけどそうでもないのでしょうか??
メニューを開く
*記述統計/最小二乗法* ①最小二乗法が最小にするのは残差平方和 ②残差平方和は残差の2乗(平方)の和 ③残差は実測値と予測値の差 ④実測値は観測データのyの値 ⑤予測値は回帰直線上のyの値 物語「最小二乗法」の主役を1人選ぶとしたら「残差」と考えます。
メニューを開く
*記述統計* 回帰直線における「yのxについての条件付き平均」という表現に慣れない場合は以下のような流れで考えてみてはいかがでしょう。 ①回帰直線はyの値 ⇒②あるxの値を与えたときのyの値 ⇒③あるxの値を与えたときのyの平均的な値 ⇒④xについての条件付きのyの平均 「回帰直線は平均」
メニューを開く
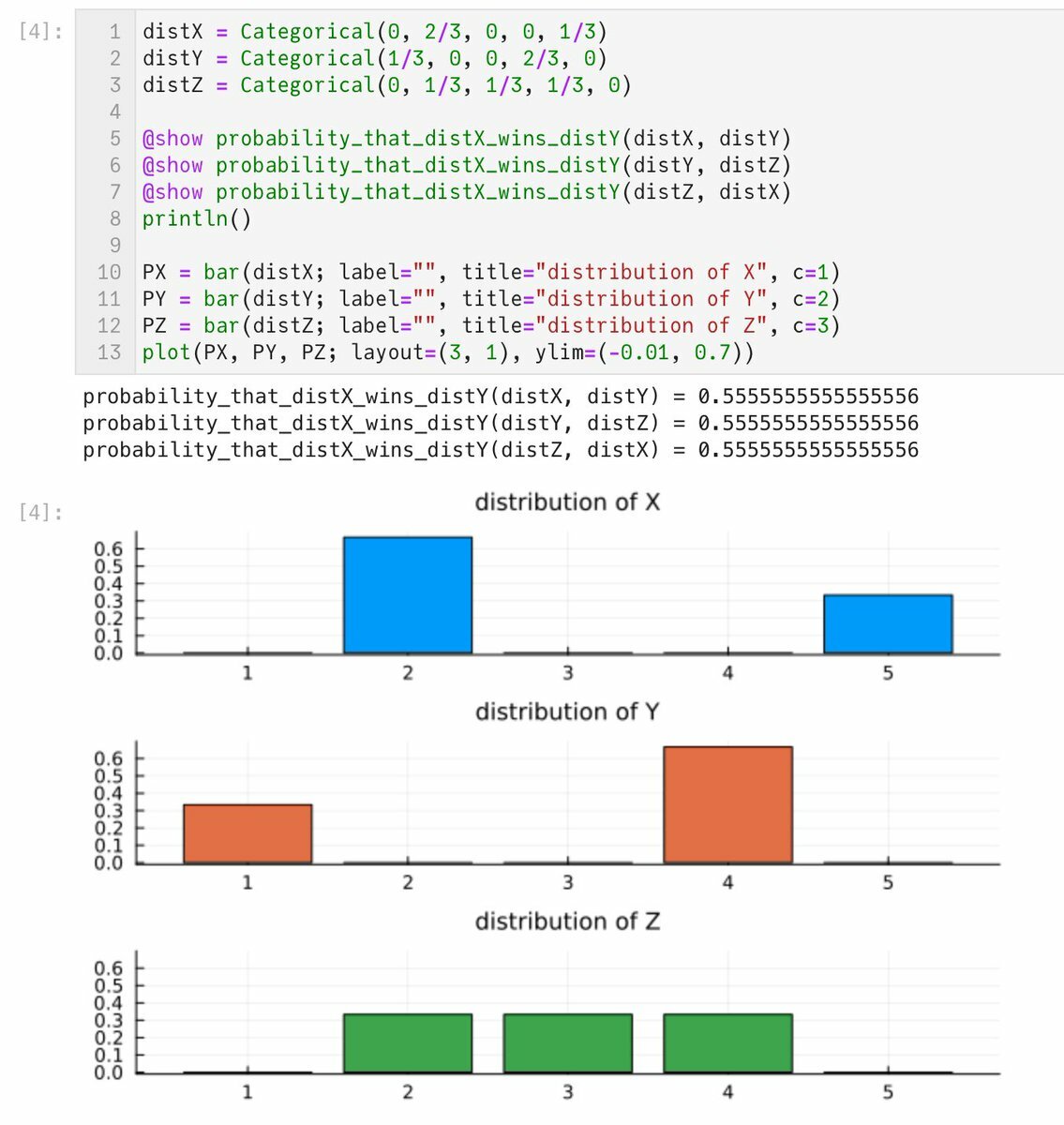
#統計 母勝率による優劣の付け方には推移性を満たさないという欠点があることに十分に注意する必要がある。 平均を見ることがいつ適切かは記述統計の話として習っているはず。左右の非対称性が大きかったり、外れ値が含まれている場合は適切でなくなる。 どの違いの測り方にも欠点がある。
#統計 Wilcoxon-Mann-Whitney検定やBrunner-Munzel検定でつけた優劣では、3つの群の間にジャンケンのような関係が生じる場合があること(非推移性)を示すよりシンプルな例を作りました。 P(X wins Y)=P(Y wins Z)=P(Z wins X)=5/9 > 1/2 となっている。
メニューを開く
| 記述統計 | 最小二乗法による回帰直線は以下3つの性質を最優先で覚えておけば大丈夫だと考えます。 ①回帰直線がデータの中心を通る ②残差の合計および平均は0になる ③残差と説明変数、残差と予測値との相関係数は0になる 最悪(怒られそうですが)暗記でも得点は可能と考えます。
メニューを開く
| 記述統計 | 回帰直線は記述統計の文脈でも論点が多い分野で、特に最小二乗法関係の論点が重要と考えます。実際、公式テキストでも最小二乗法の性質にかなりのページ数を割いていたと記憶しています。最重要は最小二乗法による回帰直線(定数項あり)はデータの平均を通ることでしょうか。
メニューを開く
| 記述統計 | 共分散を計算させる問題において、ゴリゴリ計算しても導けるけど、共分散の公式を使いこなせる場合は計算がグンと楽になる、みたいなおしゃれな問題を作成してみたいですよね。その場合、公式の第1項の「積の平均」に意味を持たせたい…売上、面積、距離、、、
メニューを開く
1万件中の審判却下の割合を記述統計的に示す文脈でないことは、他の認容、合意成立、取下げ等の割合に触れてないことからも明らかだし、会いたいのに会わせてもらえないケースをどうすべきかという質問に対して却下率しか言わないのでは回答にもなってない。
メニューを開く
記述統計と介入研究と、はたまたナラティブと、全数調査とサンプリングととか色々ガチで語りたくなった。 医療統計の先生の「安易な数字の使い方は時に人をころす」って言葉を思い出した。あの先生はPMDAの審査に関わってたからさ、薬の承認ミスったらそりゃ人の命に係わる。数字、えぐい。
メニューを開く
| 記述統計 | 分散の公式・共分散の公式は「第1項」に焦点を当てると覚えやすいと考えます。分散の公式の第1項は「2乗の平均」、共分散の公式の第1項は「積の平均」。何度も公式を忘れて苦労している方は、ぜひ、他のことは考えずに第1項だけ覚えてみてください。不思議と忘れない…かも? pic.twitter.com/D910Ie9n4V
メニューを開く
「#感染症疫学 コース」に第5回「#記述統計 #正規分布 となるものならないもの」を追加しました。 担当は、#中島一敏 先生です。 #CiDER #CiDER_EDU #note note.com/cider_edu/n/n8…
メニューを開く
でもあれか、データセットを記述統計レベルで観察して仮説を立てた上で、同じデータセットで検定をかけるみたいな流れで、これはあくまでデータドリブンの研究なので、主張はあくまで仮説に過ぎず、再現性の検証には別のデータセットが必要ですみたいなそんな感じか。
人気ポスト
じゃあ何すか、オレらがトヨタに納める部品を作るために設備投資したのにそっちの不正で生産停止になるからこっちの出荷が未定って事すか
床に直置きすると非常時の乗務員の動作に支障をきたしますし、狭い乗務員室には沢山の機器があるので、限られたスペースの中で乗務員鞄の置き場所は理由があって決められています。 通勤電車は有料の前面展望列車とは違うので、鞄の置き場まで苦情を言わないで頂きたい。
佐賀は都会なので 人妻のお持ち帰りができます
【速報】 ジョーズ、ふたたび撮影禁止になる 本日6月5日以降、ジョーズの撮影がふたたび禁止になりました #USJ_now #ジョーズ
人事がみる大学イメージ、京都大が3年連続首位 九州大2位 nikkei.com/article/DGXZQO… 総合ランキング1位の京都大学は「知力・学力」「独創性」の項目でトップに。ストレス耐性の高さを評価する声もありました。
俺が怒った時に猪を出すようにしたら、もうこれだけでビビられるようになった
昔ってベビーサークルとかベビーゲートも無かったのにどうやって赤ちゃんの安全守ってたの?って実母に聞いたら「腰紐繋げて家の柱に括り付けてた」だそうです。
後ろにめちゃくちゃポスター貼ってあるだろ
もし、東京で震度7の地震が起こったら…?
確かになんで新潟県民の俺も知らないオッチャホイをダンツは挙げたんだ?って思ったらそういう事か いや普通の人は分からんて



