- すべて
- 画像・動画
自動更新
並べ替え:話題順
メニューを開く

#統計 1936年の米国大統領選挙における民主党のルーズベルトと共和党のランドンのどちらが勝つかの予測で、リテラリー・ダイジェスト誌は約238万人分のデータを得ていたにも関わらず見事に失敗してしまった。 失敗の理由は何だったのだろうか? 続く x.com/genkuroki/stat…
#統計 1936年の大統領選挙の予測失敗の原因についてずっと誤解していたことの訂正 scholar.google.co.jp/scholar?cluste… “President” Landon and the 1936 Literary Digest Poll: Were automobile and telephone owners to blame? D. Lusinchi Social Science History, 2012 の音声概要。
メニューを開く
#統計 要するに、リテラリー・ダイジェスト誌にとって真に致命的だったのは、偏ったリスト作成の段階ではなく、無回答バイアスの問題を無視してしまったことだったのです。 以上の話をもっと詳しく知りたい人はリンク先で紹介した論文を読んでください。音声概要を聴くだけでも楽しめます。 x.com/genkuroki/stat…
#統計 1936年の大統領選挙の予測失敗の原因についてずっと誤解していたことの訂正 scholar.google.co.jp/scholar?cluste… “President” Landon and the 1936 Literary Digest Poll: Were automobile and telephone owners to blame? D. Lusinchi Social Science History, 2012 の音声概要。
メニューを開く
#統計 以下のリンク先で、データ分析の技術は 得られたデータの値と コンピュータ上に実装されたモデルの 相性の良さの様子を見るだけの道具 だとまとめたことにも意味があります。 この認識でデータ分析の技術を使えば安全で有用な技術だと分かる。有用なものを安全に有用にする説明の工夫は大事。 x.com/genkuroki/stat…
#統計 データ分析の技術は得られたデータの値とコンピュータ上に実装されたモデルの相性の様子を見るだけの道具に過ぎないので、得られたデータ外の情報の重要性を認識できない無教養な人達による権威化・権力化を阻止する必要があります。 有名人の無教養ぶりを見抜くためには教養が必要。
メニューを開く
#統計 「再現性の危機」に関する健全な議論のためには必読! scholar.google.co.jp/scholar?cluste… Forcing a deterministic frame on probabilistic phenomena: a communication blind spot in media coverage of the “replication crisis” C. Ting, S. Greenland Science Communication, 2024 の音声概要↓ pic.x.com/3kRDr9Jlfm x.com/lester_domes/s…
返信先:@learnfromerror他3人Defenses of "statistical significance" reflect conservative commitments to past usage rather than to improving science communication, and are paradigmatic examples of how such commitments give rise to elaborate rationales for resisting progress. See also journals.sagepub.com/doi/10.1177/10…
メニューを開く
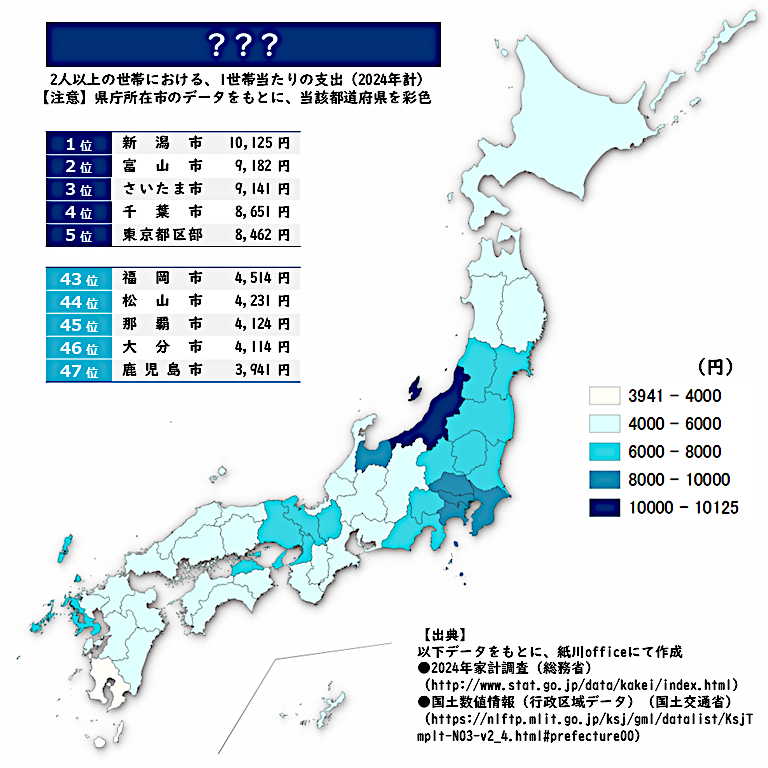
‘ おはようございます!! 【難易度:★★★★☆】 さて問題です。 これは何の支出でしょうか? <選択肢> ① コロッケ ② ハンバーグ ③ サラダ 正解は本日17時にポストします。 今日も楽しい一日を!! ★ファミマビジョンで出題中★ gate-one.co.jp/news/info/8326/ #統計 #クイズ #地理 #GIS pic.x.com/kAAaOR9SqQ
メニューを開く
#統計 以下のリンク先スレッドには、Gelmanさんのブログでの「再現性の危機」関連の記事やGelmanさん達の「再現性の危機」関連の論文を紹介しています。 Greenlandさん達と同様に安易に不正行為に帰着する議論の仕方を否定しようとしています。 x.com/genkuroki/stat…
statmodeling.stat.columbia.edu/2025/05/03/aga… (再び)ええ、ええ、皆さんが詐欺の疑いについて話している理由は分かります。でも、私たち残りの人たちにとって重要なのは、再現性の欠如と科学の欠陥であって、詐欺の可能性や非難ではありません。 2025年5月3日 Andrew Gelman 音声概要
メニューを開く
#統計 「再現性の危機」については以上で紹介したGreenlandさん達の論文は必読だと思います。 「再現性の危機」についてはGelmanさんもたくさん書いており、非常に勉強になります。 有名な"The Garden of Forking Paths"については以下のリンク先で紹介した論文を参照。 x.com/genkuroki/stat…
#統計 いやあ、これは勉強になりました。 統計分析の過程での潜在的な分岐を考慮すると意図せずに多重比較の問題が生じているかもしれないという「分岐する小道の庭」の話の整理と具体例。 sites.stat.columbia.edu/gelman/researc… The garden of forking paths Gelman-Loken 2013
メニューを開く
最新統計から見る障害年金〜がん障害年金を受給するのは難しい?〜 cancerwork-lifebalance.com/cancer-syougai… 2020年11月に書かれた記事 がん専門の社労士さん 「今年9月に初めて公開された障害年金業務統計で、その難しさがわかった」 グラフ付きで詳しく解説してます #障害年金 #統計 #がん
メニューを開く
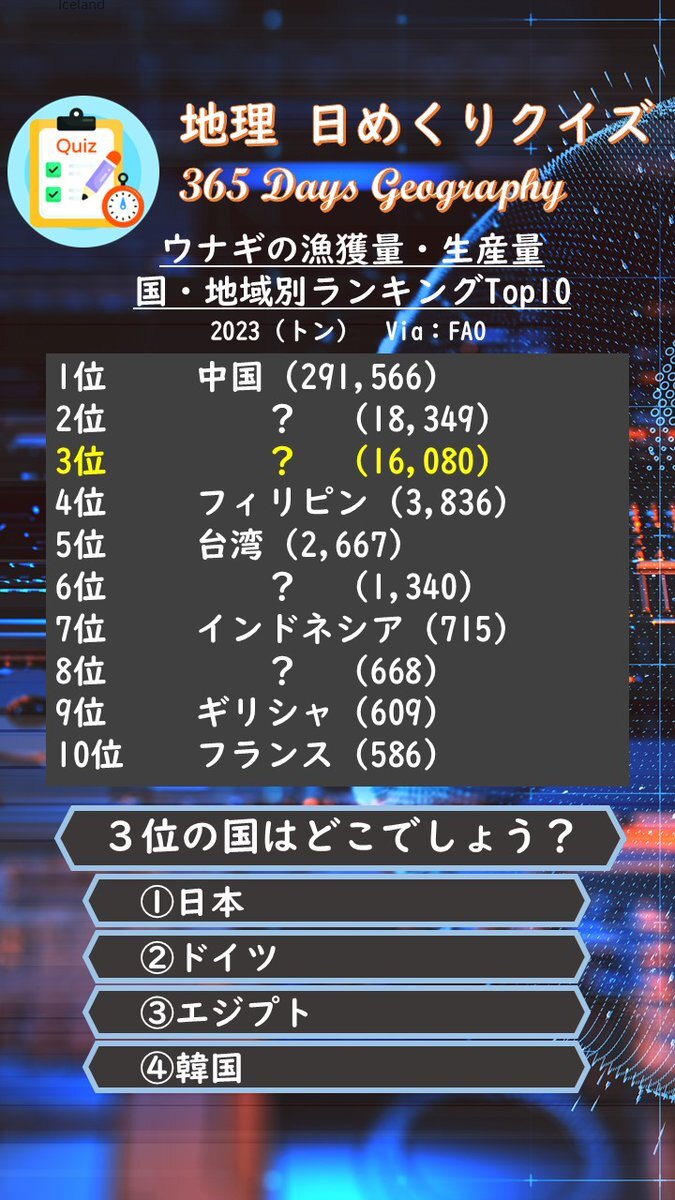
クイズ:ウナギの生産・漁獲量 3位の国はどこでしょう? 選択肢は ①日本 ②ドイツ ③エジプト ④中国 1位はぶっちぎりですね。3位までは桁が1つ違います。今回はノーヒントで行きましょう。 正解は後ほど、リポストで投稿します。 #地理 #クイズ #地理日めくりクイズ #共通テスト #統計 pic.x.com/MQ3lZNNyMh
メニューを開く
クイズ:ウナギの生産・漁獲量 1位の国はどこでしょう? 選択肢は ①日本 ②ドイツ ③エジプト ④中国 1位はぶっちぎりですね。3位までは桁が1つ違います。今回はノーヒントで行きましょう。 正解は後ほど、リポストで投稿します。 #地理 #クイズ #地理日めくりクイズ #共通テスト #統計 pic.x.com/NTGRS2jnG5
メニューを開く
#統計 以下のリンク先で紹介した論文を読み(音声概要だけでも可)、𝕏で「再現性 危機 -from:genkuroki」について検索すると「再現性の危機についてみんなダメな議論の仕方をしている」と結論せざるを得ないような感じがした。 x.com/genkuroki/stat…
#統計 「再現性の危機」に関する健全な議論のためには必読! scholar.google.co.jp/scholar?cluste… Forcing a deterministic frame on probabilistic phenomena: a communication blind spot in media coverage of the “replication crisis” C. Ting, S. Greenland Science Communication, 2024 の音声概要↓ x.com/lester_domes/s…
メニューを開く
#統計 音声概要はNotebookLMで作成しているのですが、「漢字を正しく読めない」という欠点があるので、適当に訂正しながら聴いてください。 「再現性の危機」に関する科学コミュニケーション失敗の害はすでに出ていると思います。 x.com/genkuroki/stat…
#統計 おそらくJD Vance氏が「再現性の危機」を持ち出したのは、自分達に反抗する研究者達に「最初にパンチを一発当てるため」だと思われます。お前ら研究者達は研究面でも信用できないと言いたいのでしょう。 しかしこういう「再現性の危機」の使い方は理解不足に基づいています。ただし~続く x.com/JDVance/status…
メニューを開く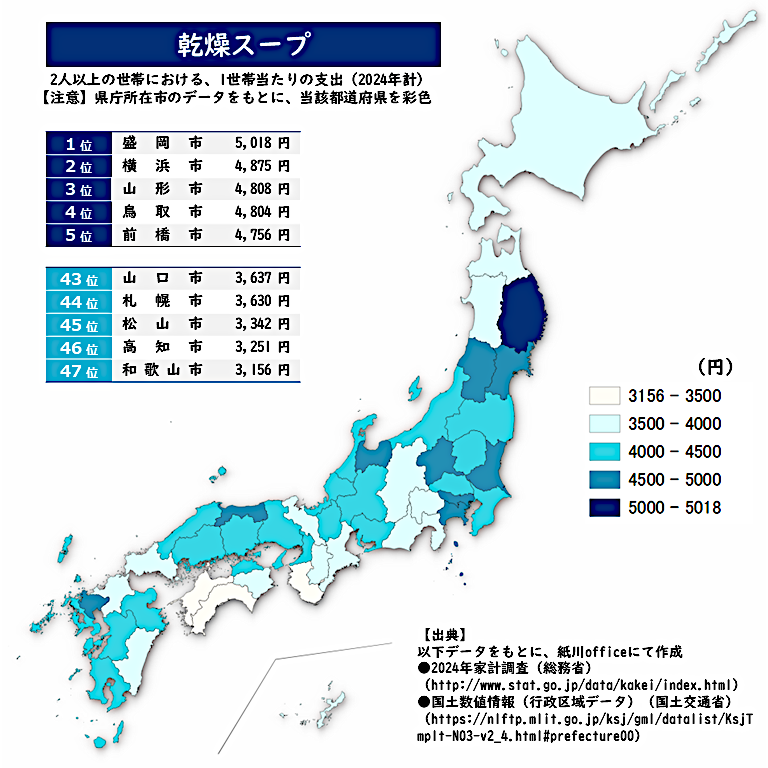
‘ 正解は・・・ <乾燥スープ> 盛岡市がトップ! 地域によって種類も違うのかな。 たくさんのためになるリプをありがとうございます。 よい夜を! ★ファミマビジョンで出題中★ gate-one.co.jp/news/info/8326/ #乾燥スープ #地理 #GIS #クイズ #統計 pic.x.com/QspMv7NEGc
メニューを開く
#統計 「再現性の危機」の歴史 風向きがどのように変わったか。 x.com/genkuroki/stat…
#統計 Gelmanさんと言えば、有名な次のブログ記事も非常に面白いです。 statmodeling.stat.columbia.edu/2016/09/21/wha… What has happened down here is the winds have changed Andrew Gelman 2016-09-21 本文の音声概要 ↓
メニューを開く
#統計 上のコメント欄 x.com/genkuroki/stat…
#統計 statmodeling.stat.columbia.edu/2016/09/21/wha… What has happened down here is the winds have changed Andrew Gelman 2016-09-21 長大なコメント欄の音声概要 ↓
メニューを開く
amzn.to/2VlRwqM 統計学が最強の学問である:西内氏の良書!!AI、機械学習、ディープラーニング、データ解析、ビックデータ。新たな技術の裏には数学と統計学とITの出会いがあった!!#数学 #統計
メニューを開く
メニューを開く
#統計 Ting-Greenland 2024を読むと、我々は「再現性の危機」に関する議論の仕方に失敗して来たことは明らかだと思いました。 科学コミュニケーター向けの内容を含むので、科学コミュニケーションに興味がある人も楽しめる論文だと思います。 x.com/genkuroki/stat…
#統計 「再現性の危機」に関する健全な議論のためには必読! scholar.google.co.jp/scholar?cluste… Forcing a deterministic frame on probabilistic phenomena: a communication blind spot in media coverage of the “replication crisis” C. Ting, S. Greenland Science Communication, 2024 の音声概要↓ x.com/lester_domes/s…
メニューを開く
#統計 「再現性の危機」関連の別の音声概要 x.com/genkuroki/stat…
#統計 「再現性の危機」に関する健全な議論のためには必読! scholar.google.co.jp/scholar?cluste… Forcing a deterministic frame on probabilistic phenomena: a communication blind spot in media coverage of the “replication crisis” C. Ting, S. Greenland Science Communication, 2024 の音声概要↓ x.com/lester_domes/s…
メニューを開く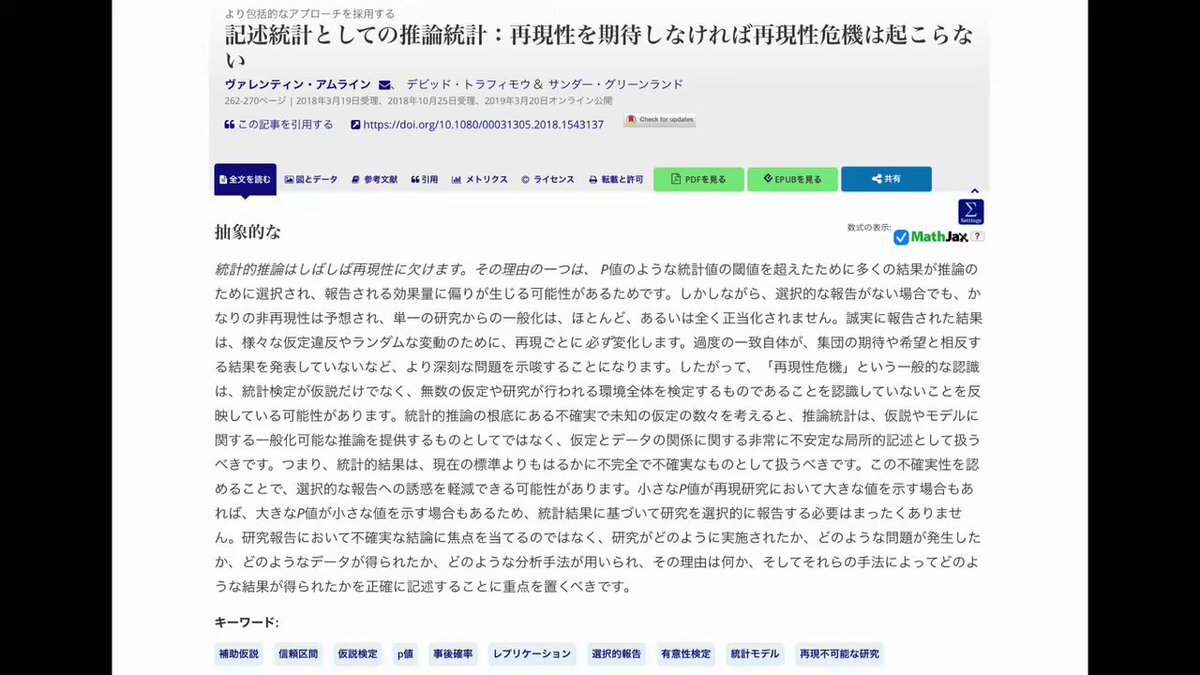
#統計 「再現性の危機」は常に鉤括弧付きで書く必要がある。 1つ上で紹介した論文と以下のリンク先の論文は必読。 「再現性の危機」に関する議論では、P値の確率論的不確実性が無視されていることが多く、通常は1つの統計分析で科学的に確立した結果は得られないという科学的常識も無視されている。 x.com/genkuroki/stat…
#統計 「再現性を期待しなければ再現性危機は存在しない」論文 scholar.google.co.jp/scholar?cluste… ↓ tandfonline.com/doi/full/10.10… Inferential Statistics as Descriptive Statistics: There Is No Replication Crisis if We Don’t Expect Replication V. Amrhein, D. Trafimow & S. Greenland 2019
メニューを開く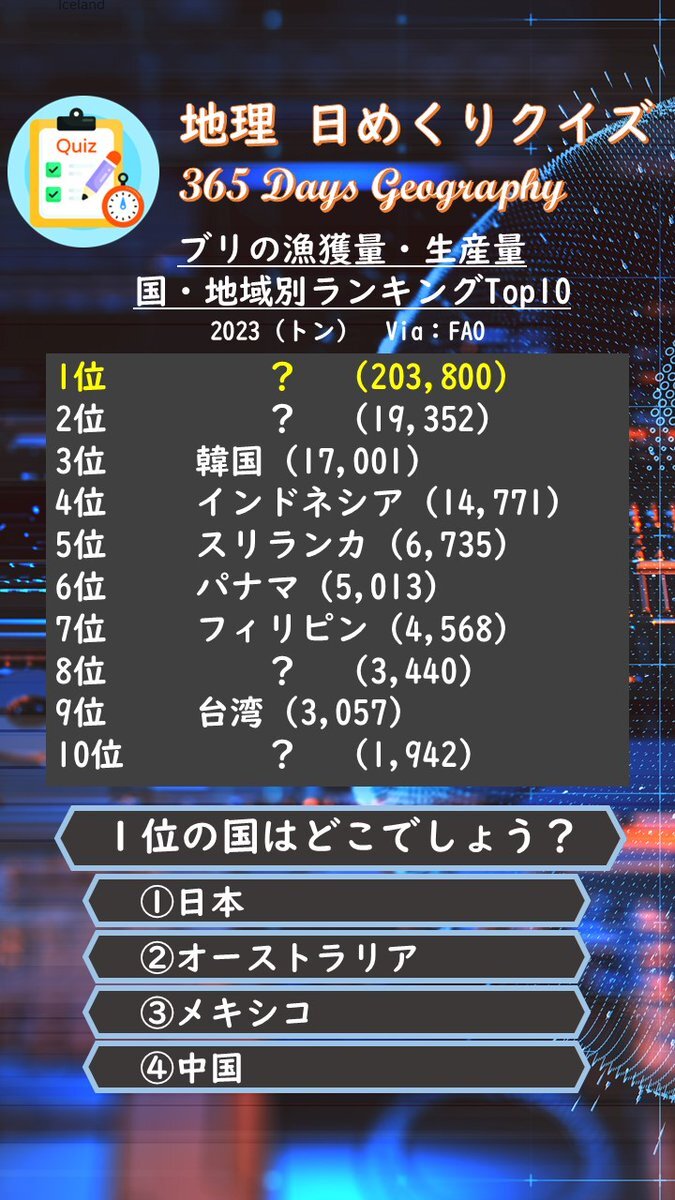
クイズ:ブリの生産・漁獲量 1位の国はどこでしょう? 選択肢は ①日本 ②オーストラリア ③メキシコ ④中国 1位はぶっちぎりトップ!天然と養殖の合計で、養殖生産量が圧倒的なのが原因ですね。 正解は後ほど、リポストで投稿します。 #地理 #クイズ #地理日めくりクイズ #共通テスト #統計 pic.x.com/gwf1FidRmk
メニューを開く
\学生向けお知らせ👨🎓/ 【エントリーは8月8日(金)まで】 独立行政法人統計センターと総務省統計局等との共催イベント「統計データ分析コンペティション 2025」が開催されます🧑💼 興味のある学生は、以下より詳細を確認し、応募ください🙋♂️ campus.internet.ac.jp/news/190559 #東京通信大学 #統計 #データ分析
メニューを開く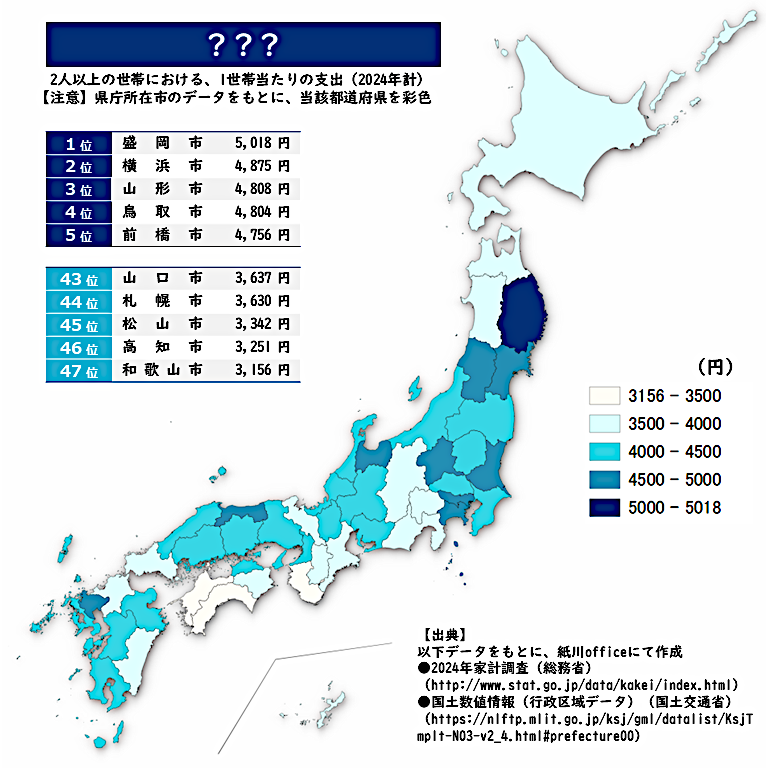
‘ おはようございます!! 【難易度:★★★★☆】 さて問題です。 これは何の支出でしょうか? <選択肢> ① 風味調味料 ② 乾燥スープ ③ カレールウ 正解は本日17時にポストします 今日も楽しい一日を!! ★ファミマビジョンで出題中★ gate-one.co.jp/news/info/8326/ #統計 #クイズ #地理 #GIS pic.x.com/j9YNENwqiI
メニューを開く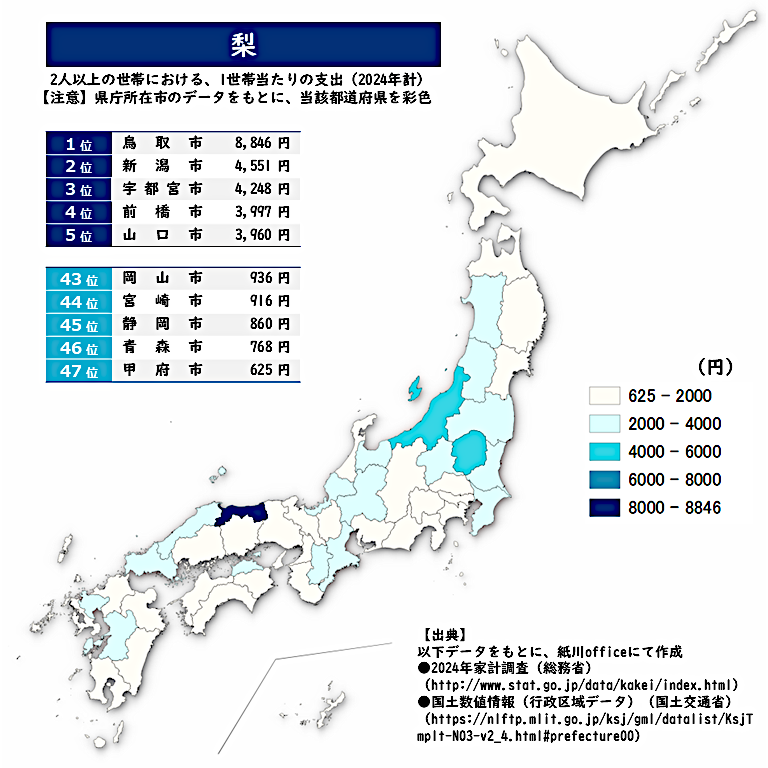
‘ 正解は・・・ <梨> 鳥取市が断トツ!! 千葉市どうした? 下位は別のフルーツがよぎります。 今日もたくさんのためになるリプをありがとうございます。 よい夜を! ★ファミマビジョンで出題中★ gate-one.co.jp/news/info/8326/ #梨 #地理 #GIS #クイズ #統計 pic.x.com/XdU0fyHFlh
人気ポスト
鬱で部屋も片付けられず、風呂も入れず、今日締切の課題もできず今これ
常磐線乗ろうとしたらこれで鬱 何故かは知らんが北千住中線に停車中の422Mの付属側が防護無線を自動発報したらしく
2kgで!?
これは水遊びスポットいっても噴水を怖がり水に足をつけることすら断固拒否な子ども
お初のお菓子でしたが、これは想像以上でお気に入りの一つに… 緑のすいとん餅でこしあんを包み竹を模ったお菓子なのですが、節に施された桂皮がその意匠、お味のアクセントに。 コシのあるもちもちのお餅、なによりもこのこしあんがなんとも濃厚かつ上品で本当に美味しい✨ 🎋川端道喜 青竹
私も、背中に見惚れていたら西国一に睨まれるモブになってきました😎✌
キルフェボンの会社の株主優待、たった100株しか持ってなくても半年に1回3,000円分のギフトカード送ってくれるの神すぎる…
素晴らしい鮮度のイワシ 私でなきゃ見逃しちゃうね
普通にコーヒー飲むつもりだったけど店員さんに勧められてまんまとアイスクリーム乗せてもらった浮かれ者👈
過去にどこかのコンビニの上に富士山が話題になってたけど、こっちはしまむらの上に武甲山だぜ!



