- すべて
- 画像・動画
自動更新
並べ替え:新着順
ベストポスト
メニューを開く

*記述統計* x+yの分散=x分散+y分散+2*xとyの共分散。 このxを回帰直線の予測値、yを残差と置き換えると、予測値と残差の和(つまり実測値)の分散=予測値分散+残差分散+2*予測値と残差の共分散、となります。 最小二乗法による回帰直線の予測値と残差の共分散は0なので(略) pic.twitter.com/nYpzc9IhmX
メニューを開く


【第5回週例会】 本日の週例会は統計セクションでした!得られたデータを数値で要約する記述統計量をRstudioを使って算出しました! ↓キソケンFacebook↓ facebook.com/letkisoken pic.twitter.com/rK1TtpT8B8
メニューを開く
*記述統計* 2級のPBT最後の試験(2021年6月試験)の功績の1つは、あれを出題されると今後教える側が回帰直線の切片と傾きの式について「暗記でOK」と軽々しく言えなくなったことではないでしょうか。少なくとも導出までのプロセスは紹介せざるを得ないと考えます。 pic.twitter.com/L4lKhOT6Ii
メニューを開く
【質問】Excelを使った統計学のテキストで、「まずこのデータ(n=100)の特徴をつかみたいです。記述統計量をまとめてみよう」みたいな例題で、標準偏差をSTDEV.S関数で出していて、この場合ならSTDEV.P関数を使う(n-1じゃなくてnで割る)べきじゃないかと思うんだけどそうでもないのでしょうか??
メニューを開く
*記述統計/最小二乗法* ①最小二乗法が最小にするのは残差平方和 ②残差平方和は残差の2乗(平方)の和 ③残差は実測値と予測値の差 ④実測値は観測データのyの値 ⑤予測値は回帰直線上のyの値 物語「最小二乗法」の主役を1人選ぶとしたら「残差」と考えます。
メニューを開く
*記述統計* 回帰直線における「yのxについての条件付き平均」という表現に慣れない場合は以下のような流れで考えてみてはいかがでしょう。 ①回帰直線はyの値 ⇒②あるxの値を与えたときのyの値 ⇒③あるxの値を与えたときのyの平均的な値 ⇒④xについての条件付きのyの平均 「回帰直線は平均」
メニューを開く
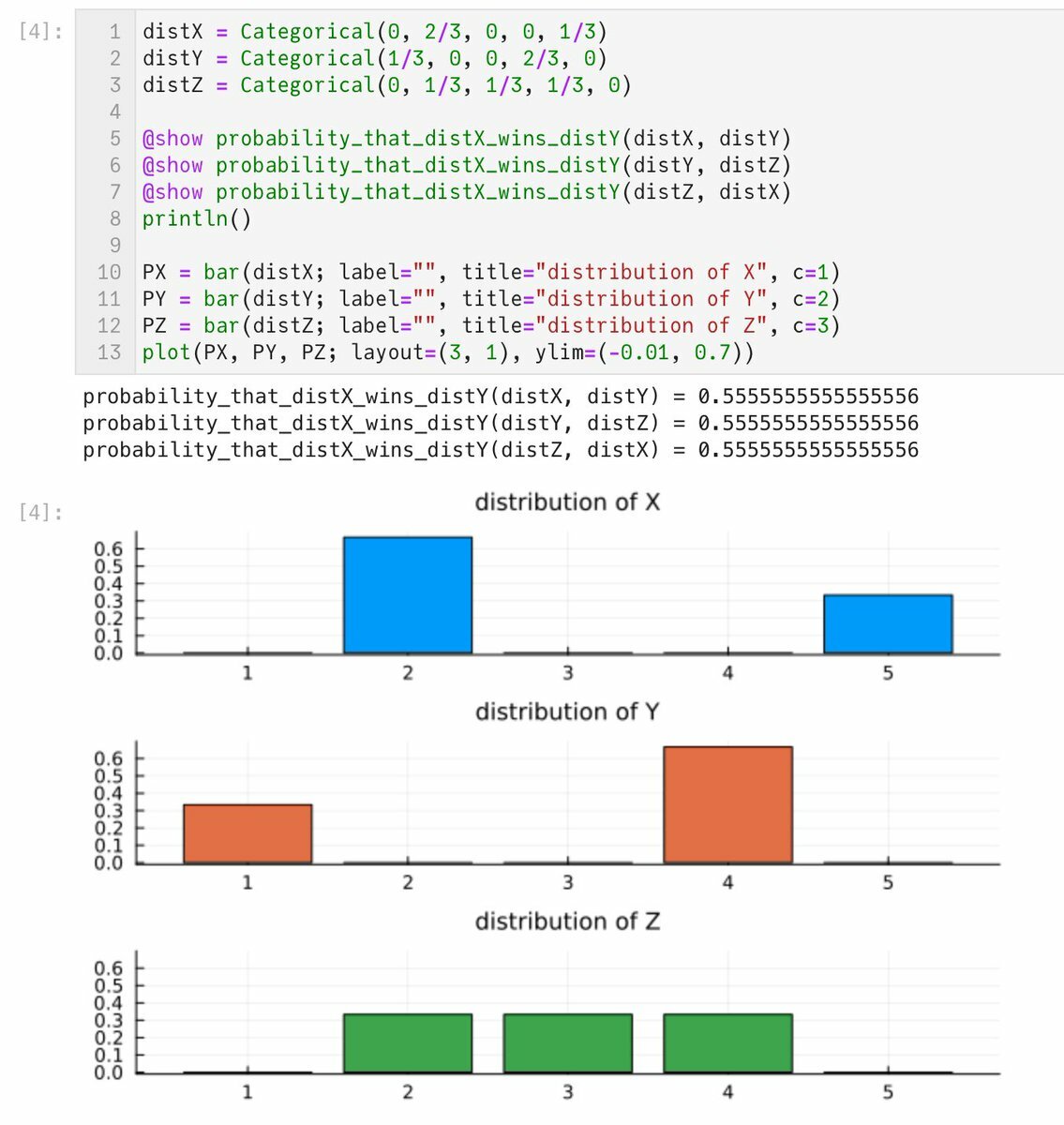
#統計 母勝率による優劣の付け方には推移性を満たさないという欠点があることに十分に注意する必要がある。 平均を見ることがいつ適切かは記述統計の話として習っているはず。左右の非対称性が大きかったり、外れ値が含まれている場合は適切でなくなる。 どの違いの測り方にも欠点がある。
#統計 Wilcoxon-Mann-Whitney検定やBrunner-Munzel検定でつけた優劣では、3つの群の間にジャンケンのような関係が生じる場合があること(非推移性)を示すよりシンプルな例を作りました。 P(X wins Y)=P(Y wins Z)=P(Z wins X)=5/9 > 1/2 となっている。
メニューを開く
| 記述統計 | 最小二乗法による回帰直線は以下3つの性質を最優先で覚えておけば大丈夫だと考えます。 ①回帰直線がデータの中心を通る ②残差の合計および平均は0になる ③残差と説明変数、残差と予測値との相関係数は0になる 最悪(怒られそうですが)暗記でも得点は可能と考えます。
メニューを開く
| 記述統計 | 回帰直線は記述統計の文脈でも論点が多い分野で、特に最小二乗法関係の論点が重要と考えます。実際、公式テキストでも最小二乗法の性質にかなりのページ数を割いていたと記憶しています。最重要は最小二乗法による回帰直線(定数項あり)はデータの平均を通ることでしょうか。
メニューを開く
| 記述統計 | 共分散を計算させる問題において、ゴリゴリ計算しても導けるけど、共分散の公式を使いこなせる場合は計算がグンと楽になる、みたいなおしゃれな問題を作成してみたいですよね。その場合、公式の第1項の「積の平均」に意味を持たせたい…売上、面積、距離、、、
メニューを開く
1万件中の審判却下の割合を記述統計的に示す文脈でないことは、他の認容、合意成立、取下げ等の割合に触れてないことからも明らかだし、会いたいのに会わせてもらえないケースをどうすべきかという質問に対して却下率しか言わないのでは回答にもなってない。
メニューを開く
記述統計と介入研究と、はたまたナラティブと、全数調査とサンプリングととか色々ガチで語りたくなった。 医療統計の先生の「安易な数字の使い方は時に人をころす」って言葉を思い出した。あの先生はPMDAの審査に関わってたからさ、薬の承認ミスったらそりゃ人の命に係わる。数字、えぐい。
メニューを開く
| 記述統計 | 分散の公式・共分散の公式は「第1項」に焦点を当てると覚えやすいと考えます。分散の公式の第1項は「2乗の平均」、共分散の公式の第1項は「積の平均」。何度も公式を忘れて苦労している方は、ぜひ、他のことは考えずに第1項だけ覚えてみてください。不思議と忘れない…かも? pic.twitter.com/D910Ie9n4V
メニューを開く
「#感染症疫学 コース」に第5回「#記述統計 #正規分布 となるものならないもの」を追加しました。 担当は、#中島一敏 先生です。 #CiDER #CiDER_EDU #note note.com/cider_edu/n/n8…
メニューを開く
でもあれか、データセットを記述統計レベルで観察して仮説を立てた上で、同じデータセットで検定をかけるみたいな流れで、これはあくまでデータドリブンの研究なので、主張はあくまで仮説に過ぎず、再現性の検証には別のデータセットが必要ですみたいなそんな感じか。
メニューを開く

#心理統計法 #スクーリング 記述統計(平均や標準偏差の意味、出し方)から始まり、推測統計、統計的仮設検定までを扱う 不安な人は統計法の復習をして臨むと良い 【テスト】 語句16問選択 計算2問 どの条件でどの式を使うかと式を纏めておくと良い(写真参照) ルート計算できる電卓必須 #聖徳大学 pic.twitter.com/JuQczNWcyu
メニューを開く
#統計 P値や尤度の解釈は、使用しているモデルを暗黙の前提にせずに、前面に持ち出して目立つようにして、 データの数値のモデルを使った記述統計 (モデルが妥当でない場合はその記述はナンセンスになる) であるかのように解釈すると安全で無難な解釈になり易い。 biostatistics.ucdavis.edu/sites/g/files/… pic.twitter.com/2WRdLhrERr
メニューを開く
| 記述統計 | 共分散の公式 [xとyの共分散] = [xyの平均]-[xの平均]×[yの平均] は共分散を計算するのに便利ですが、分散の公式と同様、この公式で得られるのは標本共分散(nで割る)ですので、不偏共分散を求める場合には [n/(n-1)] 倍する必要があります。 pic.twitter.com/7oAqvG3Zp6
メニューを開く
統計解析ソフト「エクセル統計(BellCurve for Excel)」に搭載している手法を用いて、実際にデータ分析を行なった解析事例を紹介します。 【記述統計量─エクセル統計による解析事例】 bellcurve.jp/statistics/blo… データ表の先頭行を選択して、メニューを選ぶだけで統計量の結果が出力されます。 pic.twitter.com/nKMBq4YvNc
メニューを開く
(記述統計) xとyの標準化得点をzxとzyとすると、zxとzyの積の平均は、xとyの相関係数に等しくなります。 というのも、zxとzyの積の平均は、zxとzyの共分散とみなせるからです。 zxとzyは標準化されていますので、その共分散は相関係数になります。
メニューを開く

CMOS📷カメラ「①FITS分析で使うMATLAB『プロットのタイプ』」 をまとめてみました♪ ・記述統計学、数学の参考書に出て来る「度数」「相関」「回帰」「確率分布」「正規分布」これら全てグラフ化出来ました(当たり前) まだ取り組んでいませんが「シグマ区間」「ポアソン分布」も出来る模様 続 pic.twitter.com/C8njoXtBDq
メニューを開く
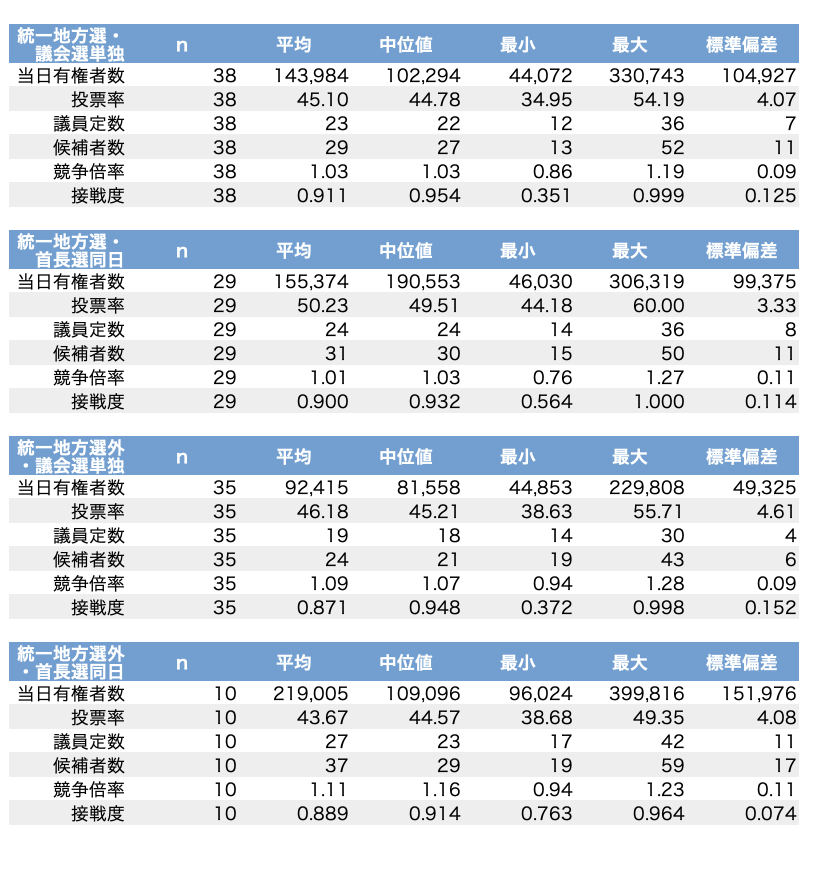
なるほどです ということで、前述の145選挙から町村を除いた市のみ (112選挙) で ①統一地方選かつ議会選単独 ②統一地方選かつ首長選同日 ③統一地方選外かつ議会選単独 ④統一地方選外かつ首長選同日 の4群に分けて記述統計量を出してみました このパターンで見ると投票率は②→③→①→④ですね pic.twitter.com/lhBjlo4IVc
返信先:@Barrettm95sp情報提供ありがとうございます。 同日の方がやはり高いですね。 今、外なのでちゃんと見れてないですが、これに統一選かどうかも影響するのかどうかは確認してみようと思います。 バレットさんからご提供いただいたデータ活かせていないのは本当に心苦しいですが活用させていただきたいと思ってます。…
メニューを開く
計量分析でいきなり統計モデル使うまえに記述統計やクロス表を見ようというのをよく言うけど、質的分析も同じでいきなりコーディングするよりデータの特徴をざっくり把握した方がいいと思うので、さっと頻出単語とかをテキストマイニングできる環境は大事だと思う
メニューを開く
返信先:@shingen_mototakそれらを含む様々な要素を観る時、現在値だけでなく変化率(微分)と蓄積(積分)という時系列上の態様、分布形状・代表値・バラツキという記述統計上の態様とも併せて観る事の重要性を再認識する機会かもしれませんね。
メニューを開く
実証分析において統計学の手法を用いるのは ①データの傾向や特徴,すなわちエビデンスを見つけるため ②得られたエビデンスが偶然によるものかどうかを判断すること の2つの理由による。①では記述統計やモデルの推定,②では統計的仮説検定が用いられる。
メニューを開く
<進捗(数日分)> (1)心理学概論 S13~15 文化心理学(個人主義/集団主義、文化的自己観) 心理統計学(尺度水準、記述統計・推測統計) 心理学を学ぶことについて(研究手法、再現性の危機)
メニューを開く
そういえば記述統計だけ手にしながら推論の域の話までしている連中を見るんだけどあの辺の界隈って統計学の域ではないからお互いに統計学未満の話しかしていない状況だからどう転んでもどっちも要らないってことにしかならないわね…
メニューを開く
現状は記述統計をメインに使ってて、 母比率推定とかの推測統計とか、過去の施策の効果をt検定とか因果推論を使って検証するみたいなこともしてます! まだまだ機械学習とか数理最適化とかには踏み込めてないので、これから使えるようになっていきたいです✨🔰
メニューを開く
【詳細2】 現在はマーケティング部に所属して、得意先の食品メーカーやトイレタリーメーカーの商品の購買データを元に記述統計を行って、その結果を元にマーケティング戦略を立てて得意先に提案したり、 社内のデータ整備や外部の購買データとかと組み合わせて潜在市場の発掘とかをメインにやってます
人気ポスト
お粥用に冷凍容器買ったけど離乳食終わったら使うのかな〜って撮ってたら腕立てしてた
スマホを買い替えた飼い主の試し撮りに散々付き合わされた挙句の表情がこれ
東京ディズニーシーのザンビーニ・ブラザーズ・リストランテのレジ奥にある壺にはラテン語で"IN VINO VERITAS"と書いてあり、その意味は「酒の中に真実がある」です。 つまり「酒に酔うと、人は隠していた本性を表してしまう」ことを表しています。
めちゃめちゃトイレ行きたいけど時間の余裕がなかったのでせや!中央線は今はトイレ付きが走ってるやん✨とホームに上がったら209と唯一分割でトイレ無いH49でガチギレしてる そんなことある?
「保育園みたいって言われたんだ」って、小2息子はもうウルトラマンの箸を学校には持っていかないらしい。保育園の頃、AEONでいっしょに選んで。ずっと宝物にしてた箸。今朝はしずかに、何も絵柄のないグレーの箸をランドセルに入れてた。
鬱病同士で同棲したら治るのか検証してる最中ですが、今のところTwitterが荒れた以外に変化がありません。
今T1で空港泊してるんやけど、前に紹介したところきたよ!めっちゃ良いよ🩷🩷 目の前コンビニだし、椅子柔らかいから痛くない!!みんな1人1つ使ってる!仕切りがあるから正確には1つのベンチに2人って感じ!! 充電器もあるし🔌.....💡 ⚠️GATEはAのところね‼️ ターミナル1 T1 仁川 仁川空港
そんなやつおるわけ
ごめんね、メニューが発表された時「ウケる!こんなん機内食じゃんwアレンデール城はここでは飛行機の設定ですかぁ?www」って思って。 俺、こんなに熱々でこんなに美味しいビーフシチューのパイ包み食べた事ないわ。 素晴らしいフライト体験をありがとう。
宣伝させてください……間借りで週1でやっているカフェにお客さんが全然来ません……紅茶のフリーフローと食パンの食べ放題で1000円です……ビーフシチューのセットもあります……ケーキも出してます……このままでは廃業もやむを得ません……大阪の住吉大社の近くです……どうか来てください……



